



Cray Courts the Enterprise with Pre-Configured Analytics Urika-GX

Cray (NASDAQ: CRAY) continued its courtship of the advanced scale enterprise market with today's launch of the Urika-GX, a system that integrates Cray supercomputing technologies with an agile big data platform designed to run multiple analytics workloads concurrently. While Cray has pre-installed analytics software in previous systems, the new system takes pre-configuration to a new level with an open, “enterprise-ready” software framework designed to eliminate installation, integration and update headaches that stymie big data implementations.
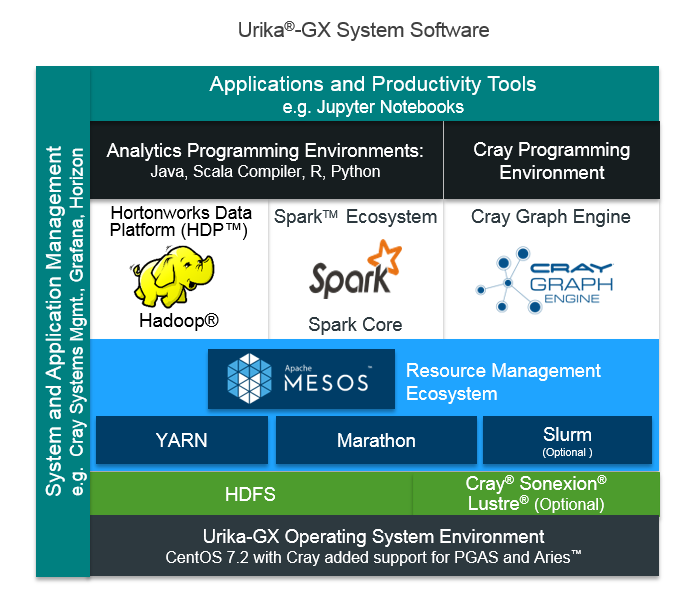
Available in the third quarter of this year, the Urika-GX is pre-integrated with the Hortonworks Data Platform, providing Hadoop and Apache Spark. The system also includes the Cray Graph Engine, which can handle multi-terabyte datasets comprised of billions of objects, according to Cray. The Graph Engine runs in conjunction with open analytics tools for support of end-to-end analytics workflows, minimizing data movement. The system includes enterprise tools, such as OpenStack for management and Apache Mesos for dynamic configuration.
The Urika-GX features Intel’s recently announced Xeon “Broadwell” cores, 22 terabytes of memory and 35 terabytes of local SSD storage capacity. Three initial configurations will be available in two-socket 16, 32, or 48 processor nodes (up to 1,728 cores per system) delivered in a 42U 19-inch rack. Cray said larger configurations will be available in the second half of 2016.
While Cray’s heritage comes out of the traditional supercomputing industry, where technology and integration staff expertise tends to runs deep, the Urika-GX is designed for the enterprise market, which generally prefers a “solutions” approach, said Ryan Waite, Cray’s senior vice president of products.

Cray's Ryan Waite
“For IT organizations, it’s hard to get these systems up and running,” he told EnterpriseTech. “Some of the big data systems they’ve bought only come with cookbook recipes, and there’s a lot of heavy lifting to the IT organization. So they buy one of these systems, it looks awesome on paper, they pull out the recipe and now they’re responsible for getting the operating system installed, they’re responsible for getting a particular version of Hadoop installed, they’re responsible for making sure that that version of Hadoop works with some other version of Spark, which works with some other version of some other tools that they’re using. And if any of those components are upgraded, or if there’s a cool new version of one of those tools that the data scientists want, the IT organization again is responsible for all that integration testing, and that can be hard.”
IT organizations also struggle with ‘frankenclusters.”
“They build one cluster for real-time data ingestion with Kafka, and another one used for ETL into a data processing system, and yet another that’s part of your Hadoop infrastructure, another one that’s part of your Spark infrastructure, so they have lots of different types of clusters,” Waite said. “That fragmentation is hard on IT organizations because it’s wasteful – some clusters are running at high utilization, others at low utilization.”
He said the Urika-GX system helps eliminate these challenges with an open, agile analytics platform that supports concurrent analytics workloads by combining Cray’s Aries supercomputer interconnect with the company’s industry-standard cluster architecture, the Urika-GD scalable graph engine and the pre-integrated, open infrastructure of the Urika-XA system.
 “Analytics workflows are becoming increasingly sophisticated with businesses looking to integrate analytics such as streaming, graph, and interactive,” says James Curtis, Senior Analyst, Data Platforms & Analytics at 451 Research. “An agile analytics platform that can eliminate many of the challenges data scientists face, as well as reduce the time it takes to get an integrated environment up and running has become a requirement for many enterprises.”
“Analytics workflows are becoming increasingly sophisticated with businesses looking to integrate analytics such as streaming, graph, and interactive,” says James Curtis, Senior Analyst, Data Platforms & Analytics at 451 Research. “An agile analytics platform that can eliminate many of the challenges data scientists face, as well as reduce the time it takes to get an integrated environment up and running has become a requirement for many enterprises.”
Cray said early adopters of the new system include life sciences, healthcare and cybersecurity companies. The Broad Institute of MIT and Harvard uses the Urika-GX for analyzing genome sequencing data and reports quality score recalibration results from its Genome Analysis Toolkit (GATK4) Apache Spark pipeline have been reduced from 40 minutes to nine, according to Adam Kiezun, GATK4 Project Lead at the Broad Institute.






