



Numascale Works with MonetDB to Extend the NumaQ In-Memory Analytics Offering sponsored content by Numascale
NumaQ comes installed and integrated with tested and integrated open source analytics software. NumaQ’s unique scalable in-memory architecture is matched to Spark's in-memory analytics engine, and to R's hunger for memory. To further promote the use of open source analytics, the Numascale team is working closely with the community on tighter integration of Spark, R and MonetDB.
Recently announced is the strengthened collaboration between Numascale and MonetDB teams optimizing MonetDB on NumaQ. → Read the press release
 Scale Out To Scale Up
Scale Out To Scale Up
NumaQ easily scales to thousands of cores and terabytes of memory for data and memory intensive workloads. NumaQ's unique scale-out to scale-up architecture allows the customer to easily add memory, cores and storage by simply adding more nodes to an existing system. This allows the customer to minimize risks, stay lean and scale their analytics infrastructure based on their current workloads and only when required.
Zero Setup - Fully Supported
Start computing once your NumaQ appliance is powered up. Save weeks of your time to download, setup, test and tune your analytics software and hardware servers and networking. NumaQ is out-of-the-box analytics. NumaQ and our network of partners will support the appliance end to end, from the server to the analytics software stack. This is your single source of support and expertise.
Terascale In-Memory Analytics Appliance
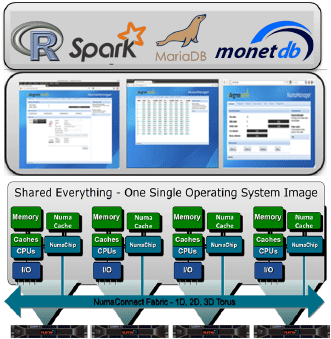 NumaQ is designed for running your largest data analytics workload in-memory. Get your results in seconds instead of minutes and in minutes instead of hours or days compared to traditional disk-based Hadoop clusters and data warehouses. Leveraging Random Access Memory (RAM) instead of traditional hard-disks, a NumaQ system can access data in nanoseconds instead of milliseconds. Leveraging Numascale’s unique shared memory interconnect technology, NumaQ systems can scale from 1TB RAM/128 cores to 16TB/2048 cores running as a single shared memory server. No cluster of operating systems or nodes to manage.
NumaQ is designed for running your largest data analytics workload in-memory. Get your results in seconds instead of minutes and in minutes instead of hours or days compared to traditional disk-based Hadoop clusters and data warehouses. Leveraging Random Access Memory (RAM) instead of traditional hard-disks, a NumaQ system can access data in nanoseconds instead of milliseconds. Leveraging Numascale’s unique shared memory interconnect technology, NumaQ systems can scale from 1TB RAM/128 cores to 16TB/2048 cores running as a single shared memory server. No cluster of operating systems or nodes to manage.
This simplicity of NumaQ, means data scientists and power users can now access a supercomputer with PC desktop-like experience with thousands of cores and terabytes of RAM.
NumaQ Spark Appliance
Apache Spark™ is a fast and general engine for large-scale data processing. NumaQ Apache Spark™ Appliance is significantly faster than a disk-based Hadoop cluster running MapReduce jobs, leading to TCO savings in terms of server infrastructure costs, software license and support costs, and cluster care and management costs.
The NumaQ Apache Spark™ Appliance is configured for optimal Spark analytics performance taking into account cpu-cores, memory and JBOD hard-disk configurations with respect to running Spark analytics workloads.
NumaQ R Appliance
R is the world’s most popular statistical programming language and environment. NumaQ R Appliance provides R with all the memory it needs for massive data set computations. Never run out of memory again for your R computations.
The NumaQ R Appliance is configured for optimal R-based analytics, taking into account R memory requirements, cpu-cores and hard-disk configured with RAID6/LVM for balanced IO/storage performance. NumaQ R Appliance includes Revolution Analytics’ R Open or R Enterprise for maximum performance, and also RStudio pre-installed and configured.
NumaQ Database Appliance
MonetDB column-store database integrated with R is the ideal platform for a database centric analytics platform. MonetDB pioneered column-store database since the early 1990’s and is today found in many leading edge databases and applications.
MonetDB innovates at all layers of a DBMS, e.g. a storage model based on vertical fragmentation, a modern CPU-tuned query execution architecture, automatic and self-tuning indexes, run-time query optimization, and a modular software architecture.
The NumaQ team is working closely with the MonetDB team to further optimize MonetDB and MonetDB/R for the NumaQ architecture.






