



Honda Speeds Past On-Site Clusters for Critical R&D

When one thinks of Honda Motor Company, the first image that comes to mind are likely of the automobiles, which wouldn’t be unnatural given that the company is a top five auto manufacturer in the U.S. and at the top of the list elsewhere in Asia. However, Honda’s business goes far beyond just automobiles, with a significant portion of revenue collected from across the motorcycle, jet, consumer, and power products divisions.
At the heart of Honda’s diverse operations is a vibrant research and development culture, almost all of which is centered around its Japan headquarters. Naturally, high performance computing infrastructure is essential for these R&D operations since much of Honda’s innovation is driven by computer-aided engineering (CAE), computational fluid dynamics (CFD), and other commercial and proprietary engineering codes.
With that in mind, one would expect that a company like Honda would have significant HPC hardware and software resources installed at each of their R&D centers, which they do, said Ayumi Tada, who leads the HPC infrastructure efforts at Honda Motor in Japan. However, as she told a crowd recently at Amazon Web Services’ Re:Invent summit recently, there is always high demand for a diverse array of systems to power their HPC-centric engineering—and there are times when even their on-site clusters are stretched to capacity.
This constant stretch brought Honda to an important tipping point—at what time was it sensible to build out cluster resources at the various centers versus take advantage of infrastructure on demand for peak need? For Tada and her team, that moment came in the summer of 2012 when a rush of demand for cores meant either extraordinarily long queue times for a deadline-sensitive R&D organization or worse yet, an extended system procurement and installation cycle that might have taken many months, if not up to a year.
This is likely a familiar situation at other companies reliant on HPC applications for their competitive and production edges, but one has to wonder, for a company the size and scale of Honda, wouldn’t they have provisioned enough resources to have at the ready for times of peak demand.
The answer is a both a yes and a no, according to Tada. The interesting thing here, she said, is that while these very considerations have made cloud a viable option for Honda’s critical R&D, the cloud has also put new pressures on the company. “Having many resources on premise is not necessarily advantageous. Competition is intensified due to the cloud. In the past, it was not always easy for smaller companies to get HPC, but those who don’t have resources at all can now calculate and use HPC easily.”
As Tada explained, “That means cloud is useful for everyone but at the same time it also a threat for a big company like Honda because small companies which could not afford the initial investment in HPC are getting competitive because of the cloud.” With that said, she does note that “cloud does offer us an opportunity as we can innovate faster than before. Even though a big company like us has many resources, we have to use the cloud efficiently and must keep improving our environment.”
These efficiencies and new capabilities afforded by the company’s adoption of AWS as a new environment for CAE applications are nothing to overlook. According to Tada, Honda was able to reduce spend on a total computing period utilizing cloud to 1/3 compared to using exclusively on-site resources. “Also, one user can make a quick decision to use over 16,000 cores at one time—the capacity is so high on the cloud that we don’t need to worry about it. By combining spot with on demand instances we saved 70%. Spot is reasonable and useful for some use cases, but for us, a combination of this and on demand instances proved best.”
To put this into production context, for one of the materials engineering codes that was eventually sent to run on AWS resources utilizing C3 instances, Tada’s team was previously tapping 80 in-house nodes and while we don’t know much about what these were outfitted with processor or memory-wise, it took over a year for the calculations to run. took four months on AWS 16,000 cores over 1,000 nodes took four – using a mix of spot and on-demand.
One bit of speculation that's worth noting here is that it was 16,000 cores as an upper limit because that was the wall for the engineering code itself. Had the code been primed, it might have been higher core counts, thus an even shorter time to result. In other words, it's not like the Japan region's AWS resources were tapped, one can guess, especially after the recent revelation of just how many millions of servers are likely powering the AWS cloud globally.
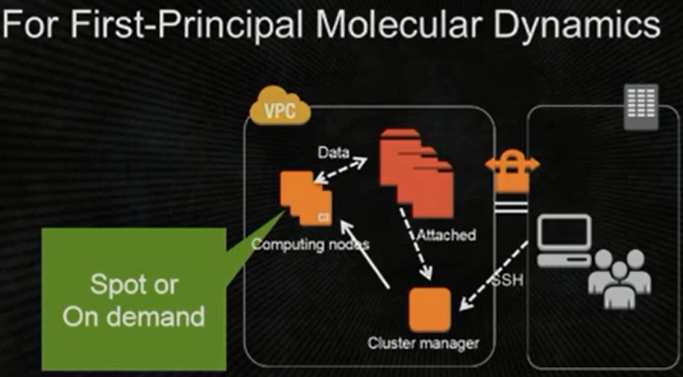 The tricky part for Honda is on the provisioning and resource allocation front. With scattered R&D teams and their complex engineering codes, it might not always be possible to tell how many nodes or cores will be required to run a job. Add to that the limitations of fighting for times in queue and balancing the needs of other teams across Honda’s several business units, and it’s clear that sheer access to resources in a timely fashion is a problem. Add to that another layer of complexity—Honda does its best to provide the right HPC infrastructure for the applications in each team, but there are times when a mix of appropriate resources is desirable. Their shift into cloud territory meant big things for their R&D agility, says Tada—not to mention freeing them from long queue times or the even more significant time hurdle of acquiring and spinning new on-site hardware and teams.
The tricky part for Honda is on the provisioning and resource allocation front. With scattered R&D teams and their complex engineering codes, it might not always be possible to tell how many nodes or cores will be required to run a job. Add to that the limitations of fighting for times in queue and balancing the needs of other teams across Honda’s several business units, and it’s clear that sheer access to resources in a timely fashion is a problem. Add to that another layer of complexity—Honda does its best to provide the right HPC infrastructure for the applications in each team, but there are times when a mix of appropriate resources is desirable. Their shift into cloud territory meant big things for their R&D agility, says Tada—not to mention freeing them from long queue times or the even more significant time hurdle of acquiring and spinning new on-site hardware and teams.
Even though the gains have been rather dramatic from Honda’s shift to cloud-based R&D, the implementation is surprisingly simple. Her team built a basic architecture with the scheduler locked into their current API. Users can then gain access to the instance types they want using SSH through VVM, then choose whether they want the spot or on-demand instances based on pricing and job requirements. They execute, run, and, following the calculation, the nodes power down automatically.
While running CAE codes in the cloud at Honda is just at the beginning phase, Tada says her team’s experiences are pushing them to look beyond what they can do in-house. She explains that although the architecture they’ve built now to address multiple R&D teams with a basic scheduler that taps their current API is not complex, they’re providing feedback to AWS about the services and needs they have going forward.
As mentioned above, among the challenges they continue to face, however, are making sure that ISV codes, of which they use many, are matching the efficiencies of the cloud to scale and hit the pricing model levels that make the the spot and on-demand instances Honda uses acceptable. While the ISV hurdle to cloud adoption for large-scale manufacturers is nothing new (not to mention the pure code scalability factor for HPC clusters no matter how their compute is delivered) it is a threat to Tada’s plans to keep pushing Honda closer to a more cloud-centric approach.
This more looming problem code-wise aside, there are still other gaps in the cloud for Tada’s team at Honda. While AWS has unquestionably been a boon for the R&D units, HPC performance on clouds, even with the newly announced Haswell-powered C4 instances for HPC folks, is an evolving concern. “We keep trying to use several kinds of computation toward the next step in CFD and CAE, but we hope that interconnect network speed between nodes will get better than the current services.” Currently, users can take advantage of 10GbE on the HPC nodes, and while Tada didn’t mention Infiniband or the possibility to AWS eventually tapping next-generation EDR, that can be assumed.
To be fair, however, AWS has worked diligently to always step up its offerings to suit the HPC application palate, generally rolling out new compute (and memory) intensive offerings not long after new Xeon generations with an HPC bent have hit general availability. Additionally, a couple of years ago they added GPU computing instances into the mix as well as pushed Intel-specific features, including AVX2 and Turbo Boost capabilities into the nodes, just as one might have in an on-site setup.
Although Tada has seen firsthand the benefits of challenges of HPC clouds for Honda, there is still the need to provide a solid TCO and ROI argument to a company that has already invested many millions into maintaining its fleet of R&D HPC systems. While she notes this will take time and the movement of more applications in AWS, she harkened back to words from her company’s founder, Soichiro Honda, who said, “Instead of being afraid of the challenge and failure, be afraid of avoiding the challenge and doing nothing.”






