



Facebook Gives Lessons In Network-Datacenter Design

Facebook's ALtoona, Iowa datacenter
Every now and again, the hyperscale datacenter operators tell the world about some new tricks they have come up with to solve a particular set of pesky problems, and then the IT industry takes notice and eventually, if the idea is a good one, it sticks. So it is with the new network design that social media giant Facebook has come up with that is coupled very tightly to its new datacenter in Altoona, Iowa.
The Altoona datacenter is the fourth facility that Facebook has built to run its own infrastructure, with the others being in Prineville, Oregon; Forest City, North Carolina; and Lulea, Sweden. Each of these facilities, which together support the 1.35 billion users of Facebook’s applications worldwide and more importantly provide the advertising and other services that makes the company its daily bread, have pushed the envelope on server and datacenter efficiency. With the Altoona datacenter, Facebook has created a facility that is cooled by outside air (as the Prineville and Forest City centers are) and that also uses the latest Open Compute server, storage, and rack designs to drive more efficiency into the infrastructure. It is even powered by a nearby 140 megawatt wind farm. But the interesting bit that people will study about the Altoona datacenter is the homegrown network architecture that Facebook has come up, which it simply calls the Fabric.
Alexey Andreyev, a network engineer at Facebook, described the Fabric in a lengthy blog post. This is one of those rare documents in the hyperscale world where something just happened and everybody who is anybody in that rarified world, as well as large enterprises and supercomputing centers, are going to study what Facebook says about the Fabric very carefully. Andreyev also posted a little presentation on YouTube as well describing the Fabric:
As Andreyev points out, the production network at Facebook is a kind of large distributed system, with its own specialized tiers and technologies for different networking tasks in the backbone of the network, at the edge, and leaving the datacenter to link to other Facebook facilities and to the outside world.
You might be thinking that with 1.35 billion users hammering on its systems from the outside Internet that the traffic hitting Facebook’s datacenters – what is called the “north-south” traffic in the network lingo – is a lot larger than the traffic between the servers and storage inside the datacenters – what is called the “east-west” traffic. You would be wrong. While the Internet-facing traffic is certainly rising very fast as Facebook adds more users and features, the east-west traffic is growing faster and utterly dwarfs the north-south traffic, as you can see from the data culled from one of its datacenters:
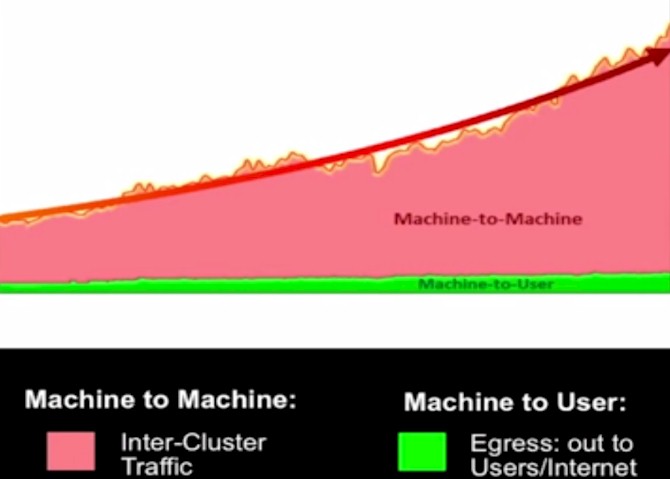
The machine-to-machine traffic is doubling in less than a year, according to Andreyev. The network design has to reflect this massive amount of traffic, and importantly, has to allow for server, storage, and network capacity to all be scaled up independently and with as little disruption and reconfiguration as possible.
With the early networks installed in Facebook’s latest datacenters, the network was built around the concept of a cluster, which was comprised of hundreds of server racks with top-of-rack switches that then fed into aggregation switches to create the cluster. Three years ago, which roughly coincides with the opening of the Forest City datacenter, Facebook moved to what it calls a “four post” network architecture, with three hot switches and a third for redundant paths that offered a factor of 10X more capacity across the cluster than the original networks. But even with this, Facebook’s cluster sizes were limited (at least relative to the hundreds of thousands of servers it has) by the port counts in the aggregation switches. These big bad network boxes are only available from a few vendors, they are loaded with complex and expensive software, and they are themselves very pricey. Moreover, Facebook was constantly trying to manage the port links between clusters – they have to share data, after all, as the company’s web and analytics and ad display systems must all eventually communicate as the Facebook application runs. The more communication between clusters, the fewer nodes that can be in those clusters.
And so, with the Fabric, Facebook has done what many of its hyperscale peers are doing: moving to a three-tier network that employs modestly sized (and therefore less expensive) switching equipment at the edge (leaf), the fabric, and the aggregation (spine) tiers of the network. While Andreyev doesn’t come out and say it directly, it looks like the social network is using homegrown 10 Gb/sec and 40 Gb/sec Ethernet switches to build out the Fabric. Here is the logical view of the Fabric in two dimensions:
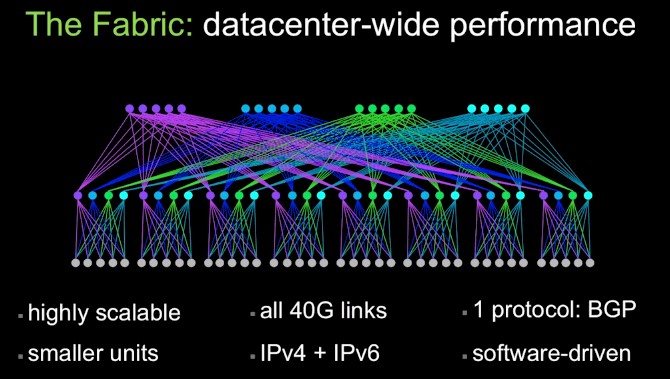
And here it is in three dimensions:

The idea behind the Fabric is to be able to make a network that can scale to cover an entire Facebook datacenter. Rather than have variable cluster sizes, as it has done in the pat, Facebook is standardizing on a pod of network capacity, in this case a unit of four fabric switches, which have 40 Gb/sec Ethernet ports. Each server rack has 10 Gb/sec downlinks to the servers (Andreyev doesn’t say how many) and four 40 Gb/sec uplinks into the fabric switches. The fabric switches in turn have 40 Gb/sec links into the spine switches. There are four different spine planes in the network, which have 12 spine switches to start but which can scale up to 48 spine switches.
“Each fabric switch of each pod connects to each spine switch within its local plane,” Andreyev explains. “Together, pods and planes form a modular network topology capable of accommodating hundreds of thousands of 10G-connected servers, scaling to multi-petabit bisection bandwidth, and covering our data center buildings with non-oversubscribed rack-to-rack performance.”
The number of paths between servers and storage in the racks is large, and is intentionally so such that if a spine or fabric switch goes bonkers the network keeps on humming. Look at all of these paths:
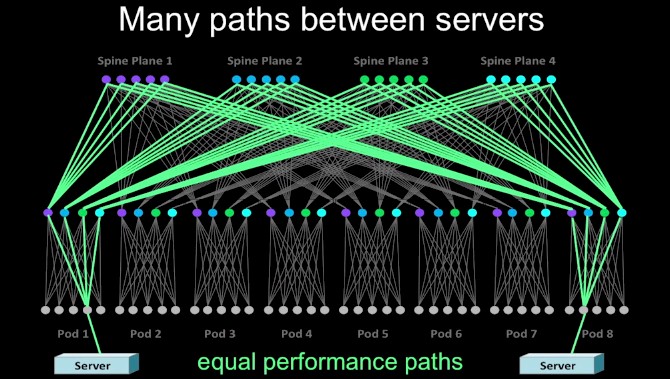
The edge switches of the network link Facebook to the outside world, and these can be scaled independently from the rest of the network. A bank of edge switch pods provides 7.68 Tb/sec of switching capacity up to the Internet backbone; these edge pods also provide inter-datacenter communications for Facebook. This can be upgraded to 100 Gb/sec switching when it becomes affordable or necessary.
The entire network fabric is implemented in 40 Gb/sec Ethernet (excepting the links between servers and top of rack switches), and it runs the Border Gateway Protocol (BGP) to do Layer 3 switching across the whole shebang, from the top of racks out to the edge switches, and Facebook can support both IPv4 and IPv6 protocols. The switches are based on merchant silicon (of course).
Scaling up is a lot easier than with prior Facebook network schemes. You add server pods and top-of-rack switches to increase server and storage capacity, and you add spine switches to boost the capacity of the network. Andreyev says that the Fabric has 10X the capacity of its prior cluster-based network schemes and can scale up to around 50X without changing port speeds. Importantly, the Fabric can still allow for segmented physical clusters to run atop this new networking setup without changing its system or network management tools.
The other interesting thing architecturally about the Fabric is that the network is now in the center of the datacenter, not off to one side in big long rows. Like this:
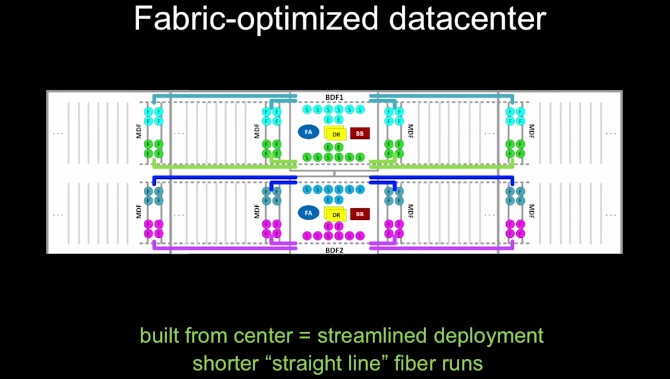
As far as racks of servers and storage are concerned, the machines reach out to four aggregation switches, just as before, in what Facebook calls the Main Distribution Frame (MDF). The spine and edge switches are pulled into the center to the datacenter into what the company calls the Building Distribution Frame (BDF). The BDFs are set up with enough fabric right from the get-go to support fully loaded data halls inside of the fully loaded datacenter, and importantly, the fiber run in nice straight lines down the server racks.
“Fabric offers a multitude of equal paths between any points on the network, making individual circuits and devices unimportant – such a network is able to survive multiple simultaneous component failures with no impact,” says Andreyev. “Smaller and simpler devices mean easier troubleshooting. The automation that Fabric required us to create and improve made it faster to deploy than our previous data center networks, despite the increased number of boxes and links. Our modular design and component sizing allow us to use the same mid-size switch hardware platforms for all roles in the network – fabric switches, spine switches, and edges – making them simple ‘Lego-style’ building blocks that we can procure from multiple sources.”
This kind of talk vindicates the leaf/spine and spline networks that upstart Arista Networks has been peddling to hyperscale shops, large enterprises, and supercomputer centers for the past several years. And it probably does not make Facebook’s switch supplier for its prior three datacenters – that would be Cisco Systems – particularly happy. Hopefully Facebook will enlighten us with its switch designs at a future Open Compute Project forum.






