



Early NVLink Tests Show GPU Speed Burst
Crunching data is not as big of a problem as moving it around so it can be crunched. The PCI-Express bus that links CPU processors to peripheral accelerators has run out of gas, and that is why Nvidia has cooked up the NVLink point-to-point interconnect for its future Tesla GPU coprocessors. The NVLink technology is still under development, but Nvidia is showing off some preliminary test results to show it has tackled the bandwidth problem head on.
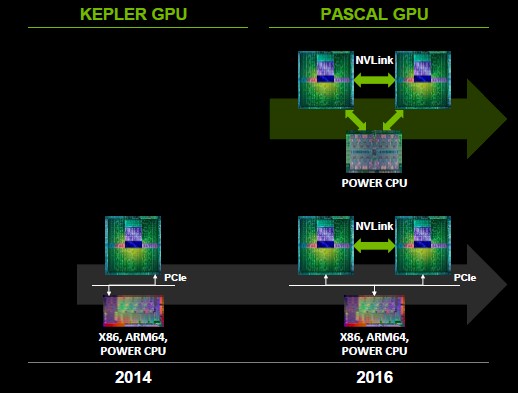
To over simplify a bit, NVLink is a superset of the PCI-Express protocol that allows for GPUs to be directly linked to each other and to also be linked to CPU processors that have been equipped with NVLink ports. The “Pascal” GPUs from Nvidia will have NVLink ports when they are delivered in 2016, and the expectation is for IBM’s future Power processor, very likely the Power8 processor that comes to market around the same time, will also have NVLink ports on it to allow for the Tesla GPU coprocessors to be tightly linked to Power processors. The initial NVLink that comes out with the Pascal GPUs will have an aggregate of 80 GB/sec of bandwidth between two GPUs. The future Power9 processors and “Volta” GPU coprocessors will also have NVLink ports, and it looks like they will run considerably faster or have more links between computing elements, providing up to 200 GB/sec of memory bandwidth between devices. The Volta GPUs and Power9 processors are at the heart of the two new massively parallel supercomputers, called Sierra and Summit and commissioned by the US Department of Energy to be built by IBM and Nvidia for $325 million.
As always, enterprises will be able to benefit from the research, development, and commercialization of technologies that are first deployed in the supercomputer centers of the world.

The initial NVLink electronics consists of a mezzanine card that snaps into the server system board and allows for multiple connections to be made between GPUs. In the Pascal GPUs, up to four NVLink connections between two GPUs in a single system. This mezzanine card is designed so systems with two, four, six, or eight GPU coprocessors can have those GPUs linked together over NVLink rather than reach out through the PCI-Express peripheral bus, which has a lot less bandwidth and much higher latency than NVLink. On a PCI-Express 3.0 x16 peripheral slot, the 16 lanes of I/O capacity deliver 16 GB/sec of peak bandwidth, but after overhead is taken out, the effective bandwidth is around 12 GB/sec. With the first generation of NVLink, each NVLink connection is running at a slightly higher 20 GB/sec and the effective bandwidth per link is about 16 GB/sec. With a maximum of four links between two GPUs, the peak bandwidth rises to 80 GB/sec and the effective bandwidth, assuming overhead that is similar to that of PCI-Express 3.0, works out to 64 GB/sec. That is a factor of 5X higher bandwidth for two GPUs communicating and sharing data over a four-port NVLink compared to linking out through a PCI-Express 3.0 bus using x16 slots. (It is actually a factor of 5.3X, if you want to be precise. And both of those bandwidths are for bi-directional traffic, moving data at those rates in both directions at the same time.)
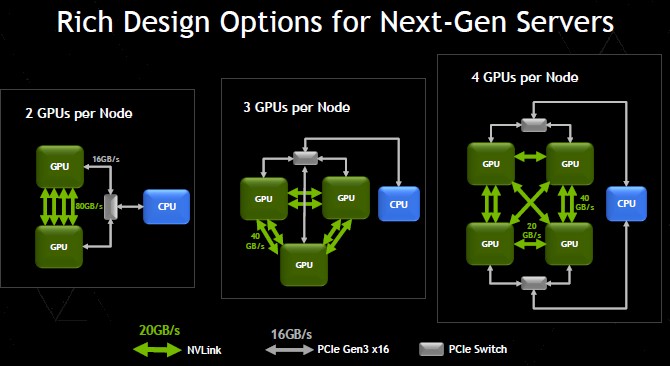
The scenarios that Nvidia is suggesting in the chart above for how CPU-GPU complexes will be linked with the NVLink 1.0 interconnect shows the CPUs being linked to the GPUs using PCI-Express switches. Unless Intel or AMD license NVLink and put ports on their chips, this is the way it will be done. But IBM is putting NVLink ports on its Power processors, and that presents some interesting possibilities. (More on that below the performance figures for NVLink 1.0.)
To give us a taste of the kind of performance boost that NVLink can provide, Nvidia ran some tests on a machine with two of its future Pascal Tesla GPU accelerators. (The results of those tests are published in a whitepaper here.) In one scenario, the two GPUs were hooked to the CPU over PCI-Express 3.0 peripheral links and also used the PCI bus to talk to each other. In the second scenario, the two GPUs were linked to each other with four NVLink ports. Take a look at the performance speedup:
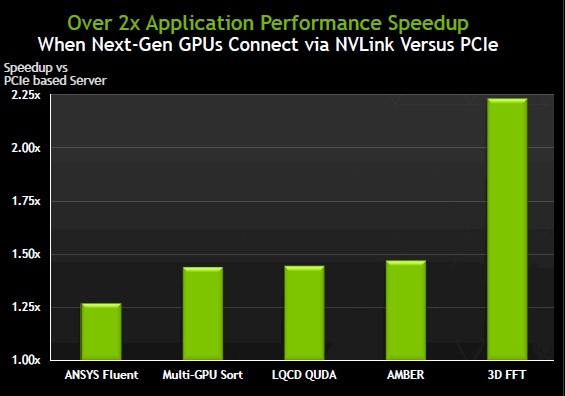
The performance increase with NVLink is lowest on the ANSYS Fluent computational fluid dynamics application, at a tad more than a 25 percent jump. The multi-GPU sorting algorithm, the LQCD quantum chromodynamics, and the AMBER molecular dynamics applications are seeing close to a 50 percent performance boost, and the 3D fast Fourier transform routines are seeing a more than 2X speed up. You can tell which applications are helped by fast data transfers between a pair of GPUs.
The question becomes what happens when you need to have an application span more than two GPUs? Will NVLink help then? We presume so. As will the extra bandwidth that seems to be on the drawing board for NVLink 2.0 and the Volta GPU accelerators.
It is not clear what Nvidia plans to do to get the bandwidth up to a maximum of 200 GB/sec between GPU coprocessors with the second generation of NVLink to be used on Power9 processors and Volta GPUs. Let’s assume that NVLink 2.0 is a superset of the PCI-Express 4.0 standard that is expected to be ratified and formalized by the end of 2015. PCI-Express 4.0 doubles up of the bit rate on PCI-Express 4.0, which will yield 32 GB/sec of peak bandwidth on an x16 slot. NVLink 1.0 ports deliver 25 percent higher bandwidth than a PCI-Express 3.0 x16 slot, so let’s assume the ratios hold for NVLink 2.0 and PCI-Express 4.0. That gives an NVLink 2.0 port running at 40 GB/sec peak. If you boost the maximum NVLink port count up to five in the Volta generation, then that gives you the 200 GB/sec of bandwidth between two Tesla GPUs and leaves one NVLink port each to link to a CPU in the hybrid processing complex. (That gives an effective bandwidth between two GPUs of around 160 GB/sec if the overhead stays the same at about 20 percent of peak bandwidth.)
Nvidia has not outlined the details on the NVLink 2.0 technology used with the future Volta GPUs or the Power9 processors from IBM, but it is our guess that it will look very much like above. But maybe not.
Considering that many systems already have four or eight GPUs against one or two CPUs in hybrid systems, you would think that the goal would be to get more NVLink ports on the devices as well as driving up the bandwidth on each port. With six ports, you could make it so four GPUs could be linked to each other with two NVLink ports each, and then you would need a few ports to weave in the CPUs, too. The ratio of ports would be changeable depending on how much communicating was done between the CPUs and the GPUs. An even smarter way to make the hybrid CPU-GPU complex might be to use NVLink to couple the GPUs together and use IBM’s Coherent Accelerator Processor Interface (CAPI), which is a subset of PCI-Express that lets accelerators link into the Power8 and future Power chip memory complex, to link each GPU to the CPU individually. That’s how I would do it, anyway. That lets the GPUs share data very fast amongst themselves (like a crazy fast GPU Direct, conceptually) and to also be hooked very tightly to the Power chip. Or, indeed, any other processor that has a CAPI port, should it be made available on ARM or X86 processors.






