



HGST Speeds Disk Design Work By 90X

HGST, the disk drive business formerly owned by IBM and then Hitachi that is now part of Western Digital, is in a constant battle with Seagate Technology and a slew of upstarts peddling other kinds of storage based on tape and flash. Improving the performance, capacity, and value of disk drives is critical, and HGST is one of the pioneering manufacturers that is putting the cloud to the test for its design and simulation workloads.
Last Wednesday, the top brass at HGST called up Cycle Computing, which has created a set of virtual infrastructure and job management tools that ride atop the Amazon Web Services infrastructure to turn it into a virtual cluster supporting the Message Passing Interface (MPI) protocol that is generally used to host modeling and simulation workloads on Linux machines. Making a disk drive and running a business that supplies and supports the devices takes a lot of computation, with applications ranging from molecular dynamics and heat transfer physics simulations, to product design, to cost tracking of the parts used in disk assembly. And, explains Jason Stowe, CEO at Cycle Computing, HGST is looking at its entire research, development, design, and manufacturing software stack as its applications and their clustered systems come up for refresh to see which ones can me moved from in-house iron to cloud-based capacity out on AWS.
One particularly pesky workload is called MRM, which is a homegrown application that runs on Linux that simulated magnetic recording media. This MRM suite is used to help design the magnetic heads that float over rotating disk drives at the end of electronic armatures. These heads read and write data to magnetic material that is sputtered onto the disk platters, and there is a lot of complex fluid dynamics and magnetism that makes the device work at the incredibly high rotations and low tolerances between the head and the platter. For all the talk about the wonders of flash, a mechanical disk is really an engineering marvel.
Creating new and better disk drives is an engineering nightmare because these devices are pushing up against very real physical limits. This MRM workload at HGST takes a design matrix of 22 different design parameters and compares it against three different media types on the platters, which generates about 1 million possible disk head designs. The MRM application sorts through the possibilities and tries to find the most sensible ones to pursue. Then there is another application that is written in MatLab that does post-processing on the output to make it easier for engineers to interpret. On an internal cluster with several hundred cores, HGST waited around 30 days – yes, 30 days – for this application to run. This severely crimps the pace of disk drive innovation.
So HGST called up Cycle Computing last Wednesday to see if there was not some way to move this MRM/MatLab application to the AWS cloud, and as Stow explains to EnterpriseTech, the techies at Cycle Computing were able to get the HGST MRM application to scale up pretty linearly up to 1,000 cores, but this job still took five days to run, which is a business week. So HGST said push the limits, and Stowe's team reckoned that with something on the order of between 65,000 and 75,000 cores, it could get the MRM application humming at the highest throughput the code could handle.
By Sunday morning, Cycle Computing and HGST were ready to go, and they deployed the MRM application across twelve availability zones in three AWS regions: US East in Virginia, US West 1 in Northern California, and US West 2 in Oregon. To boost the throughput on the MRM application, Cycle restricted its purchases of capacity on the EC2 compute cloud to the C3, R3, and selected M3 instances that sport Intel's "Ivy Bridge" Xeon E5-2600 v2 processors. These Ivy Bridge cores delivered somewhere between 10 gigaflops and 11 gigaflops of effective performance on the Linpack benchmark test, which Cycle used to get a rough gauge of the relative peak performance of the AWS compute capacity for comparison's sake.
Several years ago, when Cycle Computing was just getting started on large compute jobs, it took a month to set up a run on AWS with 10,000 cores. Now, the company can fire up a much large cluster in a couple of days and, importantly, it can get the compute instances up and running the workload quickly. This matters in a cloud computing world where you only pay for what you use.
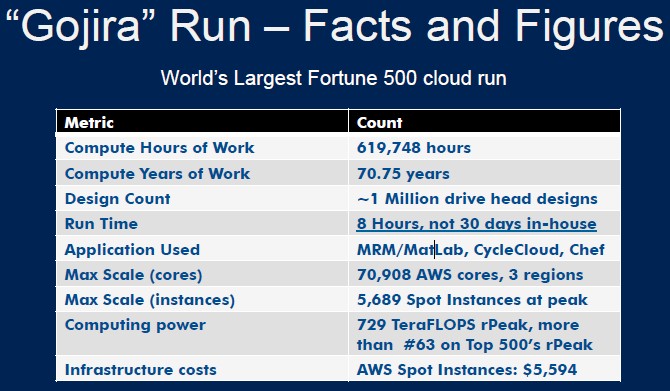
On this particular HGST MRM workload, the first 50,000 cores were up and running in 23 minutes, and the job peaked out at 70,908 cores. Unlike the MegaRun with 156,000 cores that Cycle Computing did last year to prove the scalability of its approach to supercomputing clouds on AWS, which took eight separate control servers running Cycle Server, the HGST MRM run only needed one Cycle Server instance to manage all of the capacity in the three AWS regions. The MRM matrix comparing those 22 design parameters across the three different types of media ran in eight hours. That is almost perfectly linear scaling, by the way.
Stowe estimates that it would cost around $15 million to build an in-house cluster with enough oomph to finish the MRM workload in the same eight hours, but the raw virtual compute on AWS cost only $5,593.94. The virtual cluster was comprised of 5,689 spot EC2 instances, which are not the cheapest way to buy capacity but they are the quickest and most painless. This price does not include the cost if any software licenses except for the Linux operating system on the instances and it does not include the cost of Cycle Computing's management tools, either. Stowe tells EnterpriseTech that the company does not publish list pricing, but monthly fees for the software, depending on features and usage, range from a low of $800 per month to a high of $20,000 per month.

The virtual HGST cluster on the AWS cloud, which was nicknamed "Gojira," would have a rating of about 728.95 teraflops on the Top 500 Linpack benchmark, and it would rank at about Number 63 on the most recent June 2014 rankings. Cycle Computing is billing it as the largest Fortune 500 enterprise cloud run to date.
By the way, those Ivy Bridge instances had about 50 percent more flops than the cores that Cycle Computing used in its MegaRun test last year, which used a mix of earlier Xeon E5 machines and which delivered 1.21 petaflops across those 156,000 cores for a workload run by the University of Southern California. It probably won't be long before there are "Haswell" Xeon E5 instances, which will boost the performance even further. (Perhaps this week at the Amazon Web Services Re:Invent conference in Las Vegas this week.)
You might be wondering how a workload like the MRM application at HGST can run across clusters that are in different AWS regions and not have some serious latency issues. The Submit Once feature of the Cycle Server automagically places work on the different regions and availability zones of the virtual cluster. So you don't have to do this by hand. But more importantly, the nature of the workload allow it to be run across different regions that are only linked to each other by virtual private computing (VPC) links on the AWS cloud.
Stowe explains: "One of the great things we see about this workload and others that we are running is that they may be parallel on the inner loops – they may need all of the cores on a box or need several servers on the network, but the outer loop is almost always throughput-oriented workload. We have entered the age of Monte Carlo simulation, scenario analysis, needle-in-the-haystack finding. The MRM workload is somewhat like that, in that you are looking through a haystack of drive head designs that are generated and you want to find the ones that perform best. All of these kinds of workloads lend themselves very well to cloud. Modern simulation is MPI on the inner loop, but throughput oriented on the outer loop, and because of this we can actually break the simulation up and put it back together again at key stages in the workload."






