



Eliminating the Data Junkyard sponsored content by General Atomics
Today’s high capacity scale out file (GPFS, Lustre, Isilon) and object (Cleversafe, WOS, Amplidata) storage systems make it easy to store tremendous quantities of data. As a result, many organizations are accumulating “Data Junkyards” consisting of tens of millions of files from hundreds of past and present users accumulating for years with no way of identifying their technical or business value. And because there is no detailed description of what the data consists of, organizations are afraid to remove any of it. And as capacity is exhausted the only solution seems to be repeatedly purchase additional storage. This is shown in the figure below. Look familiar?
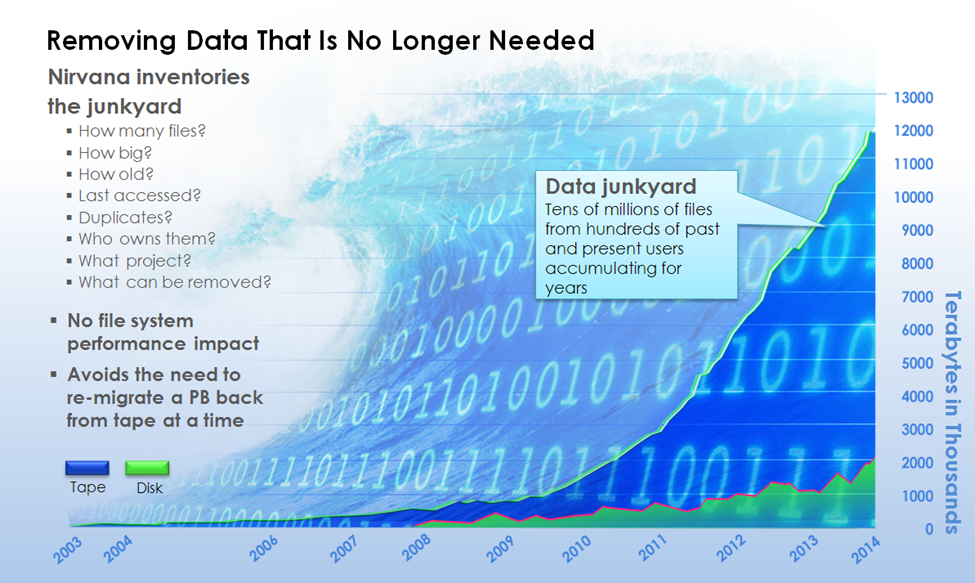
Figure 1, Reducing storage costs by removing data that’s no longer needed with Nirvana
Not surprisingly, storage vendors provide no tools to evaluate what is being stored, and analyzing the Data Junkyard by hand is hopeless. Running scanning scripts over millions of files can take days and slows the production file system. But what if you had a tool that could extract a simple inventory of the Data Junkyard in to a separate database explicitly designed for fast query and analysis?
General Atomics Nirvana can inventory Data Junkyards, characterizing the data according to size, owner, when last accessed, etc. Nirvana exposes what types of files are being stored and usage trends, by file type and user. Nirvana shows how much storage is consumed by duplicate, temporary or improper files types. With this information, administrators and managers can decide what data to keep, move or even delete.
How it works
Nirvana is an application-specific metadata management and file tracking system that inventories the Data Junkyard using a relational database explicitly designed for fast query and analysis. Nirvana performs background scans on Data Junkyard file systems and records its findings in the Nirvana Metadata Catalog. Administrators can quickly formulate and execute queries and reports over the entire catalog with no performance impact on the production file system. Nirvana identifies what data is valuable and reduces the cost of storing data, by keeping only what is needed. How many files are there? Who owns how many of what types of files? How old are they? When was the last time they were used? Nirvana builds up information to answer those questions and more, and provides information to justify data retention policies and provides continuing analysis of storage consumption.
Nirvana lets you do more with the storage you already have
With Nirvana’s reports, retention policies can be formulated and applied across all users. Files that are important to keep but not current can be moved off to lower cost storage, violations of storage policy can be detected, and terabytes of unused and unwanted data can be cleaned away. The need to buy additional expensive storage, because you do not know what else to do, is no longer necessary.
For example, the General Atomics Fusion group stores key research data on expensive, enterprise class storage. Data growth necessitated the purchase of even more expensive storage. Nirvana was used to characterize the data stored and 65% of data stored wasn’t accessed for years, multiple copies of the same data were found and one user generated over 80% of files, limiting storage system performance. With this analysis in hand, superfluous data was removed, eliminating the need to buy more storage and the usage evidence justified purchase of inexpensive tier 2 storage moving forward.
Nirvana works across the enterprise, regardless of storage type or platform.
For more information go to www.ga.com/nirvana






