



Database Hotshots Build Warehouse From Scratch For The Cloud
It may seem that the last thing the world needs is another database or data store, but a new stealthy startup founded by a team of database and analytics experts that hail from Oracle, Teradata, Actian, Cloudera, Microsoft, and Google think that the current crop of products were made for on-premises systems and are not designed to use the most important aspects of the cloud. And so they founded Snowflake Computing, which has just dropped out of stealth mode and has raised a bunch of cash to further develop what it calls the Elastic Data Warehouse.
The company's two key founders, Benoit Dageville and Thierry Cruanes, are both skiers as well as database experts, and of course there is a database schema called a snowflake and snow does come from the clouds. So they decided that this was a good name for a new cloudy data warehouse company. Dageville, who is Snowflake's chief technology officer, was a parallel systems designer at Bull and then was the lead architect for the Oracle Real Application Clusters parallel database implementation. Cruanes, who is chief architect at Snowflake, spent seven years working at IBM's European Center of Applied Mathematics on data mining algorithms before spending thirteen years at Oracle where he worked on optimizing the parallel queries inside the guts of the Oracle relational database. The company's third co-founder is vice president of engineering Marcin Zukowski, who is an expert in database query optimization and who founded a company called Vectorwise, which was acquired by Actian in 2010. The company has tapped Bob Muglia, who headed up Microsoft's Server and Tools Division and then did a stint for two years at Juniper Networks running the switch and router maker's software unit, to be its CEO.
The new Snowflake data warehouse will only be available on cloudy infrastructure and will not be available in an on-premises variant, Muglia explains to EnterpriseTech. It is not that the Snowflake data warehouse could not be run locally, but rather the whole point of the product is to make use of the elasticity and economics of the cloud to support databases and the queries that run against them. "The one thing that we will not do is sell an on premises version," he says emphatically. (Werner Vogels, chief technology officer at Amazon, feels the same way about private clouds.)
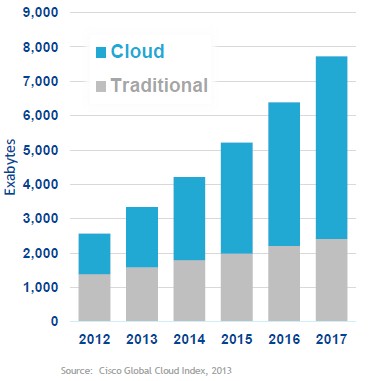
"Sometime either this year or next year, we will see more data being created in the cloud than in an on-premises environment," says Muglia, citing data from Cisco Systems. "Because the data is being created in the cloud, analysis of that data in the cloud is very appropriate. And we are also seeing customers who are creating the majority of their data on premises moving their data up to the cloud, so that is another interesting aspect."
So why not just move a traditional data warehouse up to the cloud and run it as a service? "Traditional data warehouses are based on technology that is anywhere from ten to thirty years old," Muglia explains. "And the architectures of everything that has been built in that space are for an environment that came far before the idea of cloud computing and there are a lot of limitations that exist because of that. They have 30 million lines of code that were created under the belief that data is tightly coupled with compute."
An important aspect of the Elastic Data Warehouse is that because the compute is de-coupled from the storage, you can have independent blocks of computing all accessing the same data sets but performing different queries, perhaps for different departments or application stacks, all at the same time.
Snowflake contends that companies are wrestling with transactional data coming out of the production systems as well as machine-generated data that is coming out of applications running in the cloud as well as sensors on all kinds of devices, and that traditional data warehouses do not handle the semi-structured data coming out of systems very well. And while analytics systems like Hadoop can handle the semi-structured data, they do not handle transactional data very well.
"Customers are really struggling with how they can bring these things together," he continues. And indeed, there are tools to integrate Hadoop with data warehouses and other tools that provide data warehouse-like SQL querying for Hadoop, among many other things. "In some sense, that's where the real benefit is. The transactional data tells you what has happened in your business and the machine-generated data tells you how it happened."
Data warehouses as currently implemented, Snowflake says, are complex in that you have to manage hardware, data distribution, and indexes and have limited elasticity; they are also expensive in that they need lots of care and feeding and customers generally have to overprovision for their peak loads. Hadoop, which providing less expensive storage for massive amounts of unstructured or semi-structured data, requires its own specialized skills using a relatively new set of tools, and generally, according to Muglia at least, is a batch-oriented system not designed for online data warehousing and with limited query optimization. (Plenty of Hadoop distributors would argue vociferously with this, given the new SQL and in-memory processing layers added to Hadoop.)
There are other shortcomings with traditional data warehouses that Snowflake is tackling. For one, the compute and storage in these platforms generally scale out in lockstep, and the same holds true for Hadoop clusters. But Snowflake's founders say that the architecture of the Elastic Data Warehouse service will decouple storage and compute and the metadata that describes and controls the two so they can all be scaled independently. The underlying database, which is not based on Postgres or MySQL or another open source relational database but which was coded from the ground up specifically for the cloud, will have dynamic optimization and will have relational processing extended to semi-structured data, including JSON, Avro, XML, and other data types that will be processed natively. The Snowflake service will manage the hardware and software infrastructure necessary to store data and run queries against a service level and users will not have to cope with this underlying infrastructure.
At the moment, the Snowflake Elastic Data Warehouse is running in Amazon's Western region and it will be expanded to other regions and other clouds as Snowflake's customers dictate, explains Jon Bock, vice president of marketing for the company. The data warehouse service runs on a variety of Amazon instances that have local flash-based storage, which is used to cache data from the S3 object storage service where the database holds it data. That data is stored as binary large objects (BLOBs) in S3, and the data warehouse does not in any way employ Amazon's Elastic Block Storage (EBS). Virtual warehouses are created in the Elastic Data Warehouse is small, medium, and large T-shirt sizes, and the queries can run instantly against the S3 service and get faster as the data is cached to the flash.
The hottest data is cached to the local flash in each virtual server to speed up transactions, but they all access the same central S3 BLOB storage that is the data of record for the warehouse. One of these virtual warehouses can also be used just to load data into the system, so loading can now be a continuous process rather than something that has to be done in a batch window.
The beauty of the Elastic Data Warehouse is that customers can fire up a lot of compute on the cloud, cache the data quickly, execute the queries in parallel very fast, and shut down the compute once the queries are finished. And, in many cases, this is precisely what Muglia expects customers will do.
"We can pretty much scale to any degree of scalability that people need, and they don't have to worry about managing queues and other kinds of contention," says Bock. "These are all independent islands of compute that are communicating with that separate storage tier. We realized that the rental model of the cloud really changes the game. We realized that if you rent ten resources for one hour it is basically the same price as renting one resource for ten hours, and with that kind of dynamic, it actually made sense to make a database that can take advantage of that." Hence the need to separate storage from compute.
As for scalability, Muglia says that Snowflake does not know what the maximum scalability limit for the Elastic Data Warehouse is. And Extra-Extra Large virtual warehouse is configured with 32 virtual nodes among beta customers today. "Internally, we have run it to 128 nodes with very good scalability," he says. "But that is just an unbelievable amount of processing power."

The Elastic Data Warehouse runs ANSI-compliant SQL queries, and it was built so there is no tuning required and no indexes to create. The database has crawlers that can go through the semi-structured data stored in JSON, Avro, XML< and other formats and automatically discover its structure and create appropriate schemas, which is a neat trick and which radically simplifies the use of that data.
The performance for the service is apparently pretty good. "What customers are finding is that on average this is 2X to 10X faster than whatever they had before," says Muglia. "There are some queries where customers have precise indexes on existing data warehouses where it might outperform us. But they have to do all this work to try to tune for these cases, and it turns out that these cases do not dominate the workload. The nature of a data warehouse is to be flexible, and because we are so flexible and our design was to be highly tolerant of different structures, we can outperform traditional data warehouses. And we way outperform Hadoop. Hadoop trying to do SQL is just pitiful in its performance today."
The Elastic Data Warehouse service has been benchmarked internally running the TPC-H data warehousing benchmark across 128 nodes, and has even been tested running the more challenging TPC-DS test as well. Snowflake is not divulging the performance yet, since the code behind the service is still in beta. If you are tempted to try to run OLTP workloads on the Elastic Data Warehouse, don't do it. OLTP does a lot of really quick reads and writes, while data warehousing has a load data and do complex query profile that is all reading. "We are not oriented for OLTP and we would perform poorly," cautions Muglia.
Snowflake has several paying customers for the data warehousing service now, and has another 50 customers who have been kicking it around for the past six months during the private beta testing. Elastic Data Warehouse is expected to be generally available in the first half of 2015. Muglia says that pricing for the service is being set now, and won't provide details, but says "we can crush the existing guys." The company’s announcement says it can do data warehousing for a tenth the cost of an on premises system.
That will take money, of course, as much as technology. Snowflake Computing, which was founded two years ago, has raised $26 million in two rounds of funding from Redpoint Ventures, Sutter Hill Ventures and Wing Ventures.






