



Future Cray Systems To Unite Analytics And Simulation
Big data and analytics are not a threat to Cray. They are an opportunity. And importantly, the increasingly intertwined workloads of modeling, simulation, and analytics play to the strengths of a system builder like Cray.
That was the main message of the keynote address of Cray CEO Peter Ungaro during his keynote address at the EnterpriseHPC 2014 summit last week in San Diego. Simulation, he explained using a phrase coined by IDC, was the first big data market. This is where Cray cut its teeth when it was founded back in 1972 by Seymour Cray, who was previously the system architect at Control Data Corporation, the maker of what is arguably the first supercomputer in the world in the CDC 6600.
Fast forward more than four decades and Cray is expanding beyond its founding market and staking some claims in the current big data arena and positioning itself to be at the center of a converged market where the math models behind modeling and simulation and the data models for search, analysis, predictive modeling, and knowledge discovery are glued together with data-intensive processing that captures and processes information from sensors, instruments, and other kinds of data feeds.
"The current wave of big data is very different from what that was," Ungaro explained, referring to the early simulation and modeling data that was put onto the very first Cray system at CERN. The huge volume of sensor data, Web and social media data, and other information is what is different. "At Cray, we have a pretty simple vision: We want to try to model all of this. Back in 1972, we took a physical model and put it on a computer to try to create a virtual view of the world. But more and more, people want to use computers to do data models, to take the same kinds of concepts we had in the math world and do that in the data world. We are taking the math models and streaming their output into the data models and taking the data models and streaming their output into the math models. These two things are working together, in the same world, and in the same system over time."
Conceptually, it looks a bit like this:
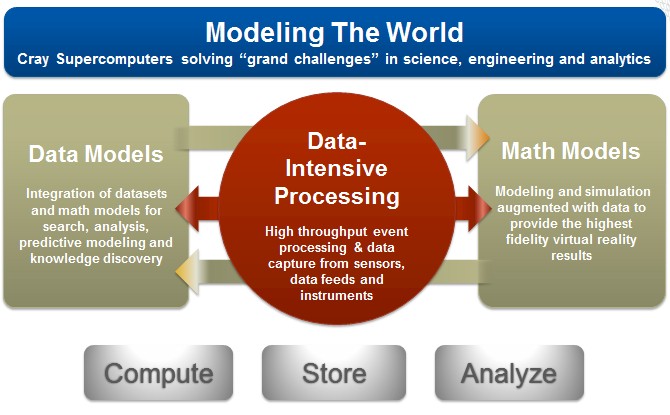
Different kinds of workloads, and that last bit – doing them in the same system – is probably a key to the kinds of systems that Cray is working on for the future. The company clearly has all of the right pieces to do both kinds of work today, and the engineering skills to build something even more interesting in the future. The "Aries" XC interconnect in the high-end XC30 implements a global memory space across hundreds of thousands of cores with very low latency, and the Urika appliance based on its "Threadstorm" processor implements a stunning 8,192 processors with over 1 million threads in a shared memory space for applications, like graph analytics, that need even tighter memory coupling. The Urika appliance, in fact, was deployed by Major League Baseball to do very deep analytics on pitchers and hitters to come up with more sophisticated ways to figure out which of the 30 teams are going to win what games during their matchups throughout the season. (Vince Gennaro, who is president of the Society of American Baseball Research and director of the sports management program at Columbia University, gave a fascinating keynote following Ungaro on how the Urika appliance was used to do broader and deeper statistical analysis on baseball players and the parks they play in.)

"This huge fire hose of information and the complexity of advanced analytics is starting to drive our thinking about architectures of the future," Ungaro said. Cray focuses on three key areas for its systems, and this includes the system interconnects, which the company is known for; its systems management and performance software, which it layers on its XC30 supercomputers, CS300 clusters, and Urika analytics appliances; and physical packaging, which allows Cray to get compute and storage density in its systems as well as upgradeability across generations. "We try to focus our energies around areas where we think we can make a big difference."
Ungaro was not about to prelaunch the future "Shasta" systems that it has been working on along with its partner, Intel. But Ungaro did provide some hints about the challenges that its "adaptive supercomputing" approach will face in the coming years, and ones that Steve Scott, the former Cray chief technology officer who returned to the company last week in that role after taking high-profile jobs at Nvidia and Google, will be taking on with the Cray engineering team.
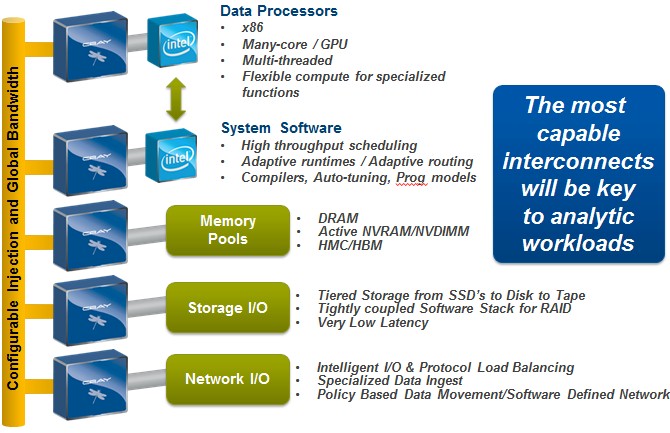
"As we start to move forward, what you are going to see is more and more things starting to get connected directly into these networks, where we can have pools of data, pools of memory," said Ungaro. "Some will be very high performance, some will be lower performance than we have today but very high capacity for doing in-memory computing. We will connect storage right into these environments and couple it much, much tighter than it is today. We will have network I/O that can do policy-based data movement across workflows in our environments. And one of the more interesting things over time is that we have a huge shift in technology in the memory and storage subsystem that I think is actually going to define the next generation of computing. People talk about exascale computing, but the more interesting thing is not how fast is the processor but how we handle our data in this whole infrastructure because this is much, much more challenging."
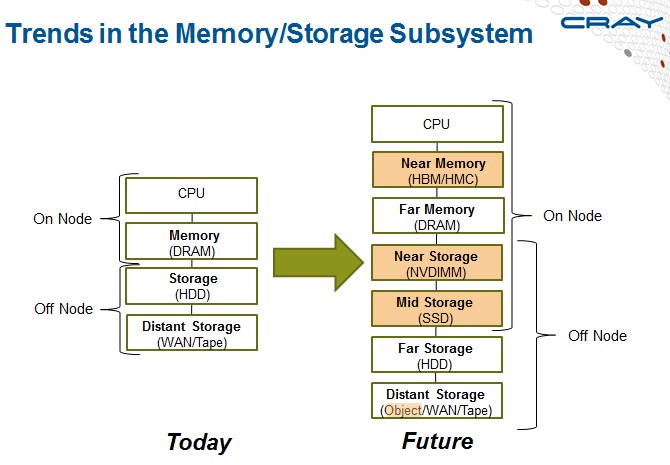
The thing that customers need, and that Cray is working on now, is an integrated environment for ingesting data, running simulations, and doing analytics. "That's what is driving what we have been thinking about at Cray in our roadmap," explained Ungaro. "Today we have different systems that do all of these different functions. What we want to do over time is to think about how we combine workflows in a single system so you don't have to move them across systems, which is a very expensive and a very difficult thing to do. How do we manage this whole memory and storage hierarchy and manage data more cost effectively and get better cost of ownership by taking advantage of that hierarchy. And how do you tightly integrate the software side and do different software runtimes across all three of these capabilities."
Ungaro said that the future Shasta systems are being designed now and will be delivered over the next few years, but in the meantime Cray would be working on some of the integrations outlined above on existing systems. A lot of this integration work is software engineering, and Ungaro said that in years gone by that about 85 percent of the research and development budget at Cray was allocated to hardware and the remaining 15 percent was spent on software. Today, the hardware R&D budget is bigger than it was back then, and 60 percent of the overall R&D budget is allocated to software.






