



Shared Memory Clusters: Observations On Persistent Memory
The other SMC articles in this series have referred to a notion called "memory." These articles have often intentionally not said so, but I have left the impression that we are talking about DRAM DIMMs. DRAM (Dynamic Random Access Memory) is dynamic because it would lose its contents if not periodically refreshed or if the power went away. This SMC article is going to widen that notion of "memory" to include something else relatively new in the computer industry, a notion being called Persistent Memory for short, or more precisely Byte-Addressable Persistent Memory.
So what is Persistent Memory? You may be thinking that we are referring to spinning disks drives (HDDs) or flash-based memory also in the I/O subsystem as SSDs. Sorry, no. They certainly provide persistence for your data and disk drives have been doing so since, like, the beginning of time. (Well, 1956.) But we are talking about a form of persistent storage a lot closer to the processors and so it is a lot faster. With this, your data can be known to be safe from the likes of power failures in a matter of a handful of nanoseconds rather than a spinning drive's milliseconds. Using what we'll be talking about below, it is also using technologies more reliable than flash.
A characteristic of the SMC memory assumed so far is that any given byte of it is addressable by any processor in the cluster using a unique real address. Although not strictly required, it is useful to also think the real address' high order bits as representing the physical location of that memory; high order bits could represent such a particular processor chip to which the memory is attached or even the node containing those chips. Lower order bits address bytes within that memory block. A different type of address, your program's – your process', your location-independent – higher level address provides you the right to access into that memory via the processor's address translation capability. Most memory is also capable of being accessed through each processor's cache. Our Persistent Memory shares these characteristic.
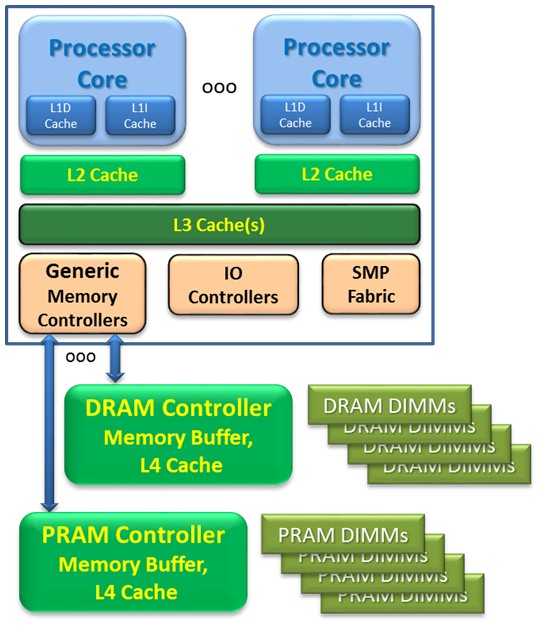
We have also been showing each processor chip as having a Memory Controller with some number of busses talking to the memory itself. That can be and is often the case. Consider, though, this figure. This time the Memory Controller is labelled as a Generic Memory Controller which, in turn, talks to some number of relatively intelligent chips which, in turn, drives the actual access to the DRAM DIMMs. This happens to be the memory topology of the recent IBM POWER8. The intent of the Generic Memory Controller is to allow new memory technologies – such as those we are discussing here - to be developed and attached to this processor chip by merely plugging in this new memory. You'll also see that we've here built upon this very notion by adding a similar memory controller chip of a Persistent RAM, here merely called PRAM for short.
What Is It?
So what kind of technologies fit into this notion of persistent memory. What follows is a quick overview with links to a few of them in no particular order:
- Phase-Change Memory (PCM, PCME, PRAM, PCRAM): The material's phase – organized or unorganized – of a class of alloys known as chalcogenides can be changed electrically. Differing resistivity for these states represents the ON or OFF of a bit. Leaders here include Micron where, at this writing, their associated web page reads "Micron continues innovating with PCM. After two generations of PCM process technologies, we're developing a follow-on process to achieve lower cost per bit, lower power, and higher performance. PCM is one of several emerging memory technologies that Micron is investing in."IBM has also recently prototyped a storage subsystem based on PCM.
- Resistive random-access memory (RRAM or ReRAM): This also resistivity-based material can produce conducting or non-conducting paths (filaments) based on a voltage used to create or destroy these paths. Leaders here appears to be Crossbar and Micron-Sony.
- Correlated Electron Random Access Memory (CeRAM): This is a variation on RRAM which does not require the creation of filaments. "Instead the CeRAM is based on a metal-insulator transition that occurs throughout the crystal structure based on quantum mechanical electron correlation effects, according to academic papers published by Professor Araujo in recent years. This can be considered as a quantum mechanical tuning of electron bands in the material due to electron-electron effects within atoms". (Quoted from ARM Support Claimed for Non-Filamentary ReRAM by Peter Clarke.) Symetrix seems to be a driving force behind this technology.
- Magnetoresistive random-access memory (MRAM): State is stored via the magnetic alignment of storage cells (magnetic spins). A clearing house on this technology can be found at MRAM-Info.com and it provides a nice list of the organizations involved here.
- Memristor: Based on the information available, it is difficult to determine whether this term describes a particular type of device, a class of devices, or a form of persistent memory driven by Hewlett-Packard. Still, it is very clear that HP intends to incorporate what it is calling a memristor in its future system, which it is calling "The Machine." A recent article on this can be found in EnterpriseTech.
What is the point? There is very active work going on. It may not be here today, but you can see it coming in the not too distant future. And when new memory technologies do arrive, they have the potential of significantly changing the storage topology of near future systems; this is also essentially what we have been saying about Shared Memory Clusters. Picture this technology coupled with that of SMCs.
How To Use It
Using persistent memory is more complex than just plugging it into a system. For example, suppose your program arranged for some data to be stored into a system's persistent memory. And then a power failure occurs. Not to worry you say; the data is in persistent memory. Yes, it is, but where? Your program is not likely to be in control of every storage location – every byte – of persistent memory than it is even today using volatile memory.
Instead, you'll want to have abstractions supported that effectively refer to the underlying persistent memory. For example, today, do you ever think about where on a spinning disk your data resides? Some few folks do, but instead your programs refer to an abstraction such as a file in a file system or a database table within a database management system. If pressured, you know that your data must reside on disk somewhere in order to be sure that it is available after a power failure.
The abstraction could be anything, just as long as your program believes that the data is persistent, and that it can be recovered even from our persistent memory somehow.
As a case in point, here is some work being done by Microsoft in preparation for the day in which systems really do contain the byte-addressable persistent memory. It is called Microsoft BPFS, or Byte-addressable Persistent File System).
Or consider HP's direction for "The Machine." HP intends to rewrite a fair portion of Linux to avoid the need for pushing a file to a spinning disk. That file may simply reside in persistent memory, memory with enough infrastructure to allow any part of what you consider to be persistent to be found again the next time the system (and/or the operating system) is restarted.
But perhaps the best examples come from the IBM i operating system (a.k.a., iSeries, AS/400). It has many of the abstractions and much of the support already in place, with many of these existing since its inception. We are going to spend some time here taking a look at some of these.
IBM i is an object-based operating system. Based on whatever need – like the creation of a database table or a file or a user profile, what have you – IBM i creates objects out on I/O-based persistent storage. As with object-oriented programming philosophy, you normally have no idea concerning its organization, and the OS provides you with a set of operations that go along with that object. But key here is that when the object gets created, it is also created in a system-wide address space that IBM i calls Single Level Store (SLS). In the context of this article on persistent storage, it happens that SLS is also persistent; if you restart the OS – say after a power failure – the objects remain with the same address. Said differently, every byte of data out on your hard or solid-state drive has a corresponding location-independent high-level address used by the OS. If your program wants to reference that byte in whatever object, your program just uses the byte's address, no matter how many times the OS was restarted.
With today's basic system, that of processors attached to volatile memory with that complex connected to I/O-attached persistent memory, the volatile memory – the DRAM – acts as a cache for the contents of the persistent memory. Your program makes a change to an object residing in the DRAM – an object still known even there via its SLS address – and later the OS arranges for that change to be written to the persistent memory, still using that SLS address. The only difference was that if the power failed right after your change is made within volatile memory, that change is lost. If that change just happened to have made its way out to persistent memory, when the power comes back on and the OS is restarted, there's your change sitting there waiting for you. Again, the DRAM is just a volatile cache for the persistent SLS-addressed data on your hard or solid-state drive.
So now we add byte-addressable persistent memory as described above. We want some of our data – or objects – to reside there. To do so, the OS adds an attribute on your object that essentially allows you to say "I'd like this object to reside in very fast persistent memory." The OS says OK and arranges for that object's portion of the SLS address space to be mapped onto some portion of this processor-attached persistent memory.
To explain further, IBM i supports a general-use object called a User Space. A User Space object can be named, much like a file, and is persistent. But it really is a portion of the SLS address space; once this object is created at an SLS address it stays at that address as long as the object exists. Your program can provide the OS the User Space's name and the OS gives back to your program the object's address. Your program can put anything, in any format, any structure, into this object. It's just persistent address space. That's today. Now, let's define for this object that it ought to reside in byte-addressable persistent memory. The OS maps the object's address space onto this physical and persistent memory. It's named so that your program can always (re)find the object. Cool enough, right? But here's the real beauty. Every change to this object is very nearly immediately made persistent; again, this is made persistent without a need to separately write the pages of the object to I/O-based persistent storage. Fast.
That's the upside to this approach. But there is a caveat, one that every OS would need to deal with. If you've read the SMC article on cache, you also know that programs think that their changed data is in memory the moment that the processor stores the program's data. No, it is not in memory; it is available but not residing in the DRAM. Every processor of a cache-coherent SMP (or here cache-coherent SMC) and any I/O device accessing that memory can see the changed data pretty much the moment the data is stored by a program, but the store proper only changes the data block in that processor's cache. In effect, other processors and I/O devices can get the changed data block from the processor cache; the hardware does that – this being one of the most complex parts of SMPs – and programs don't need to worry about it. If the data did happen to reside in the DRAM, processors get the data from there.
Again, that is the point? Recall that this is a discussion about making data persistent. The program stored data in the processor's cache and believes the data is in memory, perhaps in persistent memory. It isn't really, at least not yet. Normally, in the fullness of time, that changed data block may well make its way into memory, due largely to the normal aging of a processor's cache lines. But programmatically, you don't know when. If it's still in the cache and in a changed state, it's not in memory and so also not in persistent memory.
All those words are to bring you to this point. The processor hardware does provide the means to push the changed contents of a cache into memory. When you really do want the data to be persistent, the hardware provides the means of doing it. However, most programming languages don't know anything about a processor's cache. Some means needs to be provided for your program to actually say "be persistent now." Just as with the IBM i's User Space, your data written there might actually occasionally be written to an I/O-based persistent storage device, but your program can't know for sure unless it forced the data out there. The same thing holds with persistent memory and the processor's cache.
Articles In This Series:
Shared Memory Clusters: Of NUMA And Cache Latencies
Shared Memory Clusters: Observations On Capacity And Response Time
Shared Memory Clusters: Observations On Processor Virtualization
After degrees in physics and electrical engineering, a number of pre-PowerPC processor development projects, a short stint in Japan on IBM's first Japanese personal computer, a tour through the OS/400 and IBM i operating system, compiler, and cluster development, and a rather long stay in Power Systems performance that allowed him to play with architecture and performance at a lot of levels – all told about 35 years and a lot of development processes with IBM – Mark Funk entered academia to teach computer science. [And to write sentences like that, which even make TPM smirk.]He is currently professor of computer science at Winona State University. If there is one thing – no, two things – that this has taught Funk, they are that the best projects and products start with a clear understanding of the concepts involved and the best way to solve performance problems is to teach others what it takes to do it. It is the sufficient understanding of those concepts – and more importantly what you can do with them in today's products – that he will endeavor to share.






