



Google Mesa Data Warehouse Scales Like No Other

Search engine giant Google is talking about another innovative data store that it has come up with, perhaps spawning yet another round of innovation in the open source community that often mimics what Google does to solve complex scale issues. Google plans to talk about a massive data warehousing system called Mesa at the 40th International Conference on Very Large Data Bases, which is being hosted in Hangzhou, China from September 1 through 5. The team of Google software engineers that created Mesa have put out their paper on the data warehouse to give their peers a chance to noodle it ahead of the conference.
Google is one of the most innovative hardware and software developers on the planet, and it is one that has only one direct customer – itself – even though it has billions of indirect customers – those of us who use one or more Google online services. Because of the vastness and complexity of its operations, Google runs into scalability and performance issues in its infrastructure well ahead of most organizations on the planet, and that is one reason why the company spends so much on IT development.
The company is mostly secretive about what it does, but every now and then it puts out a paper describing a tough problem and how it solved it, usually many years after the fact and often after it has come up with a better methodology than that paper contains. The Google MapReduce data munching algorithm and the Google File System (from 2001) spawned the Hadoop project, and the BigTable distributed data storage system (circa 2004) was the inspiration for Cassandra and a number of other NoSQL data stores. Ideas from BigTable's successor, a geographically distributed database called Spanner that runs atop of BigTable, and Colossus, it geographically distributed file system and a successor to GFS, are out in the wild, and now so will be ideas about the Mesa data warehousing system.
All of this research and development does not come cheap, and that investment absolutely underpins the dominant market share that Google has in search and online advertising and is able to maintain through constant innovation is scale and scope.
Just to give you a sense of investment that Google makes, let's compare it to IBM, which is a legendary R&D firm and always tops the patent lists. IBM had $99.8 billion in sales in 2013, and spent $6.23 billion on R&D and brought $16.5 billion to the bottom line. That works out to 6.2 percent of revenue for R&D spending and 16.5 percent of revenue dropping to the bottom line. Now check out Google. The search engine and advertising giant had $59.8 billion in sales in 2013, and spent $7.95 billion on R&D and brought $12.9 billion to the bottom line. If you do the math, Google spends 13.3 percent of revenue on R&D and brings 21.6 percent of revenues to the bottom line.
The Mesa data warehouse stores metric data that underpins Google's AdSense, AdWords, and DoubleClick online advertising business, and as the paper points out, it was necessary to create separately from existing data stores and databases because of the unique requirements of this business. (You can bet that Google doesn't want to create yet another way to ingest, store, and process information if it doesn't have to.) But look at the scale here: Mesa has to process millions of row updates per second into the database, which has petabytes of capacity, and chews through millions of row updates per second and processes billions of queries that grab data from trillions of rows per day.
And no matter what is going on with the software and inside the hardware, Mesa has to be reliable, fault tolerant, and highly scalable. Google also needs for the Mesa data warehouse to be spread across multiple datacenters – as much for fault tolerance in case it loses an entire datacenter as for localized processing to reduce latencies. The telemetry data from Google's ad serving is not just given to customers buying ads or those being paid for running ads, but are the basis for billing customers as well as to provide massive data sets on which ad delivery can be fine-tuned to target specific surfers with the right ad.
The challenges with Mesa are huge, but clearly not insurmountable because it exists and is in production. Among other things, Google knew that the data warehouse had to have atomic updates, which means updates to any particular field relevant to a query in the relational database have to all be updated for a query to execute, and the updates have to be consistent as transactions run, even when data is pulled from multiple, geographically distributed databases. The eventual consistency of many NoSQL data stores cannot be used with Mesa because, to put it bluntly, we are talking about money here, not just clickstream data. Google's Mesa designers were told it could not have a single point of failure, which is tough but not impossible, and furthermore they would need to be able to update millions of rows per second and have the data available for querying across different database views and datacenters on the order of minutes after the data has been ingested. Mesa was also designed for two classes of users: customers looking at live reports of their ad contracts with Google and batch users extracting data from many customers for reporting purposes. The design goal was to have an overall query throughput of trillions of rows fetched per day and to satisfy point queries with a 99 percentile latency on the order of hundreds of milliseconds. (About the attention span of a Web surfer.) This query performance had to scale with compute nodes and storage capacity as the Mesa system grew.
The Mesa data warehouse runs atop the Colossus distributed file system and the BigTable data store and makes use of the MapReduce approach to support queries; the Paxos distributed synchronization protocol created for Spanner distributed database (which keeps everything in synch with atomic clocks and GPS signals on a global basis) is also used for Mesa. The Mesa warehouse uses BigTable to store metadata and Paxos to keep it synchronized and in lockstep.
Google's researchers point out that most commercial data warehouses cannot ingest data at a continuous rate while also processing near real-time queries; they tend to do updates to the data warehouse every day or week, and of course, that means the data is partially stale by definition. The closest thing to Mesa, they concede, might be Hewlett-Packard's Vertica transaction database. Google's own in-house data stores – namely BigTable, Megastore, Spanner, and F1 – have the scale to attack the advertising data warehousing problem. But they say that BigTable does not have the level of atomicity needed by Mesa applications and that Megastore, Spanner, and F1, which were all created to do transaction processing, have strong consistency across geographically dispersed datacenters but they cannot ingest data at the speed necessary to support Mesa users.
Here are the clever bits. First, Mesa has a versioning system for updates to the data warehouse. Any update of the data streaming in is applied complete, across all rows, before it is released to be queried. Updates are given a version, and importantly, so are queries, which means an application never sees a partially finished update to the database. The database updates are packaged up in aggregates and applied in batches, and there is a particularly hairy scheme to do this that reduces the storage space required for storing the changed information and cuts down on the latency compared to updating data as queries come in specifically for that data. (A bad approach, and one Google did not take.)
The Mesa service runs on tens of thousands of servers in the Googleplex that are shared across many Google services and data analytics applications. Mesa is meant to run across multiple datacenters to ensure that incoming information is ingested continuously and that queries can also be run without cessation. The trick – and here is where database designers will pay attention to what Google has done – is that the critical metadata describing the data warehouse and changes to its information are replicated synchronously across those datacenters running Mesa, but the actual application data streaming in is replicated asynchronously. Updates get caught up eventually and consistently, but the metadata is always kept in lockstep. This is the trick that allows for high data ingestion even across disparate datacenters.
Inside of a local datacenter instance, the two parts of Mesa – the update/maintenance piece and the query piece – run in a decoupled fashion, allowing them to scale independently of each other. All of the raw data is stored in Colossus and database metadata is stored in BigTable. The update/management engine loads updates to data, performs database table compactions, applies schema changes (which do not affect applications, which is a neat trick), and runs table checksums and other tasks to optimize the data for queries. As in most Google systems, there is a central controller with distributed workers:
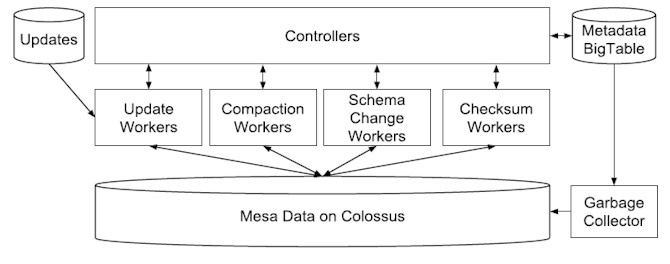
Each Mesa instance running in multiple Google datacenters is completely independent and stores a full set of the advertising data. There are load workers that copy Mesa tables from one datacenter to another as each new facility is built. Once all copies of the tables are loaded onto the new Mesa cluster, update workers in the system apply changes to the data in batches until it is in synch (or, more precisely roughly in synch because it is asynchronous) with the other Mesa instances. If a Mesa table gets corrupted in one facility – and this does happen – the load workers are used to move a copy over from a known good version in another datacenter.
To parallelize updates and queries across the Mesa cluster, Google uses the tried and true MapReduce framework it invented so many years ago.
Each Mesa cluster uses hundreds to thousands of server nodes, depending on the datacenter. (Why they are not more or less all the same is an intriguing question and probably has to do with the vintage of servers in use at each datacenter.) In the paper, Google shows performance specs for one Mesa cluster that ingests data from hundreds of concurrent sources, and on one data source alone, it read in 30 to 60 megabytes of compressed data per second, which added 300,000 new rows to the database and updated between 3 million and 6 million distinct rows. The updates were applied to the database every five minutes or so and took from 54 seconds to 211 seconds to complete. As for query processing, Google averaged processing over a one week period, and this cluster could do 500 million queries per day, accessing data from between 1.7 trillion and 3.2 trillion rows in the data warehouse. (It is not clear how many rows are in the Mesa data warehouse, but it looks like it is many tens of petabytes at the very least, by my back-of-envelope math.)
Here is a very interesting chart that plots out data growth, CPU usage, and query latency over time for a two year period.

That tells us that Mesa is at least two years old, and very likely older than that. The chart also shows that Google had some tuning issues early on, but is keeping query latencies in a much tighter range. The Mesa clusters are configured dynamically, atop software containers and using the Omega controller, and they dip in size sometimes as conditions dictate. Google did not explain what those conditions are, but it seems to happen once a year or so.
Google is also showing that the system scales up linearly as query servers are added to the Mesa cluster, with 32 nodes doing 2,000 queries per second, 64 nodes doing 3,000 queries per second (a slight dip there) and 128 nodes doing 6,000 queries per second.
One interesting tidbit: The predecessor to the Mesa system was run on what Google calls "enterprise class" machines, which presumably means large NUMA servers with big fat memories and integrated disk storage. With Mesa, Google shifted to its commodity cloud server infrastructure for compute and the external Colossus file system for data storage. This, the researchers say, has simplified capacity planning and makes the case for Google to either design and build its own high-end NUMA machines (wouldn't that be fun. . . ) or to move everything to the cloud and work it out with software.
"While we were running Mesa's predecessor system, which was built directly on enterprise class machines, we found that we could forecast our capacity needs fairly easily based on projected data growth," Google says in the paper. "However, it was challenging to actually acquire and deploy specialty hardware in a cost effective way. With Mesa we have transitioned over to Google’s standard cloud-based infrastructure and dramatically simplified our capacity planning."
With that initial system, Google also assumed that schema changes would be rare, and as it turns out, they are frequent as applications and services change at a faster pace, and thus Google advises that a design for a replicated data warehouse like Mesa should be "as general as possible with minimal assumptions about current and future applications." Integrating disaster recovery and high availability from the get-go is also advised by Google; the system before Mesa did not have such capabilities and it was a hassle when a datacenter was taken offline for upgrades. This sort of thing happens at Google with the sort of frequency that large enterprises take down racks. Google also is very careful to do incremental deployment of new features to Mesa. So it has created private instances of Mesa that have a subset of data for developers to play with, and then it also has a shared testing environment that incorporates most of the Mesa production data to see how new features will play out before they are rolled out in production. Google is also careful to stage an update to the Mesa code incrementally and to see how it works in one datacenter before it starts deploying it across all datacenters. Just like Mesa has versioning for data updates, it has versioning for Mesa clusters.
And the final challenge Google faces with Mesa is one that all hyperscale companies, and indeed most large enterprises with sophisticated software engineering teams, face: Large teams with newbies coming in all the time. Clean code, documentation, operational drills, cross-training, and other boring things are vital to make sure engineers know how Mesa and its underpinnings work and how they can – and cannot – change the Mesa data warehouse without breaking it.






