



Applied Micro Plots Out X-Gene ARM Server Future

At the Hot Chips 26 conference being hosted in Silicon Valley this week, upstart ARM server chip maker Applied Micro is presenting details on its roadmap for its X-Gene family of 64-bit processors. The ARM server ramp is taking a bit longer than many had expected, but Applied Micro is keeping the pedal to the metal with a drumbeat of ever-improving processors on the horizon.
Gaurav Singh, vice president of technical strategy at Applied Micro, gave EnterpriseTech the low-down on the X-Gene roadmap, which will result in ARM server chips that are as scalable and intricate as those that are being put together now by Cavium, Broadcom, and AMD.
The X-Gene1 processor, code-named "Storm" after the X-Men superhero, is in production right now and will be appearing in machines that are for sale by various vendors in the next few months. The X-Gene-1 chip is expected in HP's Moonshot ultra-dense servers and was featured in servers from SoftIron and Eurotech back in late June at the International Super Computing event in Leipzig, Germany. Up until now, Applied Micro has been a little vague about some of the feeds and speeds of the X-Gene1 chip, but at Hot Chips it put out proper block diagrams and talked about what is in the eight-core chips.
Applied Micro was the first full licensee of the ARMv8 architecture, and as such it is allowed to create its own cores and other parts of the system-on-chip as long as it maintains instruction set compatibility. (Some ARM licensees take whole cores as created by ARM Holdings, the company behind the ARM collective, and only do unique engineering around those cores. This is what AMD is doing, for instance, with its Opteron A1100 processors, which are sampling now and will ship in the fourth quarter.)The X-Gene 1 processors are implemented in a 40 nanometer process from Taiwan Semiconductor Manufacturing Corp and have been sampling to partners since early 2013; the X-Gene1 chip started shipping at the end of March this year.
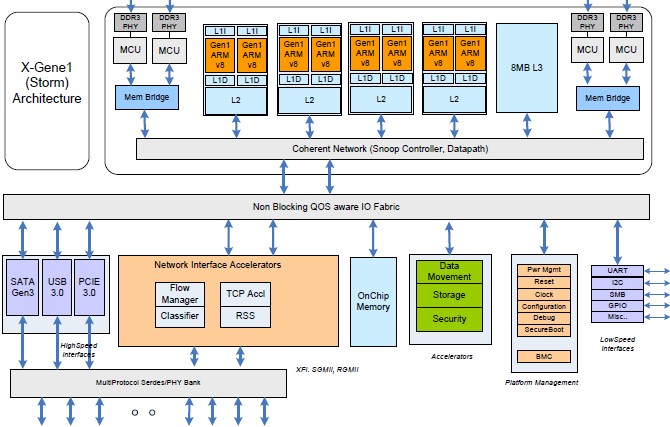
The X-Gene1 has cores that clock at 2.4 GHz. The cores have a superscalar, out-of-order execution microarchitecture that is four instructions wide and the chip can be chewing on more than 100 instructions in flight in various parts of what is called a processor module. This module has a pair of cores, each with their own Level 1 instruction and data caches, grouped together and sharing an L2 cache. Multiple processor modules are cookie-cuttered onto the die and connected by a high-speed coherent network. An L3 cache that has 8 MB of capacity hangs off of this coherent network, and so do two DDR3 memory controllers, each with two channels, and an I/O fabric. This I/O fabric can drive four 10 Gb/sec Ethernet ports and other kinds of network function accelerators; the chip has six PCI-Express 3.0 slots and an unknown number of SATA3 ports (eight is the logical number to have, giving one drive per core, a ratio that is good for certain analytics workloads).
The design is very similar, conceptually, to Intel's "Avoton" C2000, which is based on the "Silvermont" Atom core, and AMD's "Seattle" Opteron A1100 bears some resemblance to it as well structurally.
With the X-Gene2, which Applied Micro talked a bit about in June at ISC, Applied Micro is doing incremental changes to the processor microarchitecture and is adding Remote Direct Memory Access to its Ethernet controllers to reduce latency.
Singh shared the table he drew up three years ago when he was mapping out the interconnect fabrics for the X-Gene family of chips, and it shows why the company ultimately decided to stay with Ethernet:
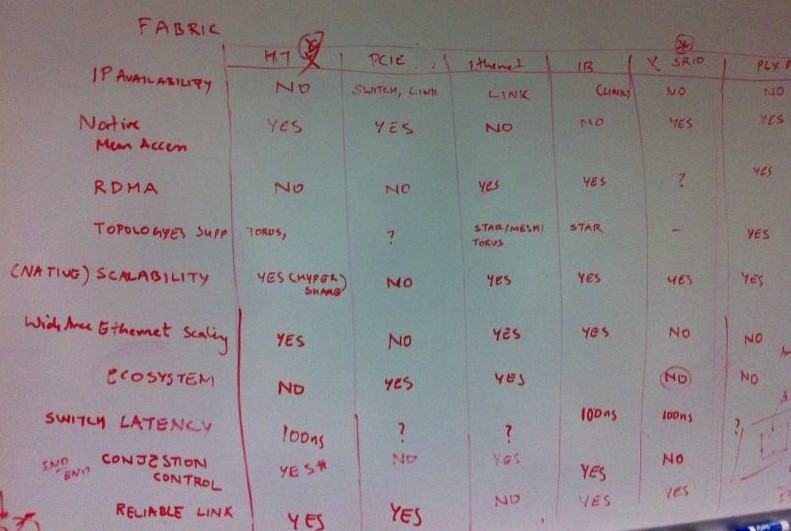
Because Applied Micro was targeting hyperscale workloads and has only now begun to see some action in the supercomputing realm with ARM being married to Nvidia Tesla GPU coprocessors, it didn't make much sense to use InfiniBand as the interconnect between X-Gene chips. Ethernet rules in the cloud and among hyperscale operators.
"What we realized is that changing the link layer in the network would not be the way to go," explains Singh. "So we decided to keep Ethernet and do something on top of that."
Support for RDMA over Converged Ethernet, or RoCE, gives 10 Gb/sec Ethernet some of the low-latency capabilities that used to only be available to InfiniBand. And it allows companies to use standard API interfaces for networking as well as existing libraries and, in many cases, existing switches in the core of the network. The resulting decrease in latency for Ethernet means transaction latencies go down, which in turn allows the processors to do more work because they are not waiting for data to come over the network. Better networking increases the utilization of the server. So, for instance, by shifting to RoCE, the application latency drops by nearly an order of magnitude, from 40 to 50 microseconds with X-Gene1 running plain vanilla Ethernet and TCP/IP to 5 microseconds for X-Gene2 using RoCE, according to Singh.
This lower-latency Ethernet is a key driver behind Applied Micro's goal of trying to improve the performance at a constant latency of a rack of machines by a factor of 2X to 3X over equivalent X86 platforms in use today. (More on that in a moment.) There are other improvements with the X-Gene2, which is code-named "Shadowcat" in keeping with the superhero theme. (The block diagram for Shadowcat is essentially the same as for Storm, although there are some differences in the chip layout.)
The overall X-Gene design is fundamentally the same but with a die shrink using TSMC's 28 nanometer process. Singh says that the X-Gene2 cores have microarchitecture improvements to help goose performance, and the clock speed is upped by a bit to 2.8 GHz. At a constant frequency, the core changes add somewhere between 10 percent and 15 percent more performance, and then the clock speed adds another 17 percent or so. But it is the RoCE support in Ethernet that is going to make a big difference, given that a lot of modern workloads run on clusters and the nodes all talk to each other as the work progresses – this is so-called East-West traffic, as opposed to the North-South traffic of a simple Web application feeding simple HTML pages out to the Internet.
To sum it up simply, X-Gene2 is about having the thread performance in the core be in better balance with the networking, Web front ends, search engines, NoSQL data stores, data analytics work like Hadoop, and media serving. These applications run on clusters with thousands of cores and the communication between threads running on those server nodes is the bottleneck; they want higher bandwidth and even more importantly lower latency. For these applications, several ratios are important: memory per thread, memory bandwidth per thread, cache size per thread, I/O throughput per thread, and storage capacity per thread are key, says Singh. Clock frequency matters, but only up to a certain point.
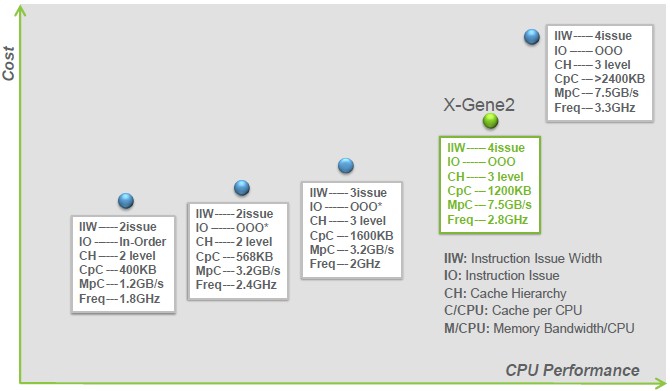
In the chart above, Singh compares various ARM and X86 processors to the X-Gene2 on these metrics. The chip profile furthest on the left if what is expected of the ThunderX ARM processor from Cavium, which will have a lot of cores but which might be a little light on the memory bandwidth and cache memory capacity. The next blue dot to the right is the profile of Intel's eight-core Avoton C2000, which does better on all fronts that Singh is comparing. The one to the right after that and to the left of the X-Gene2 is AMD's Seattle Opteron A1100, which is a little low on the clock speed but has a more sophisticated core and more cache per core. Way up high on the right is a Xeon E5-2600 v2 processor from Intel, which offers more performance in the aggregate but which also will cost more than what Applied Micro plans to charge for its chip.
On initial benchmark tests, the initial X-Gene2 chips are showing good gains over X-Gene1. On the SPEC2006_rate processor benchmark suite, the X-Gene2 is offering nearly 60 percent better performance per watt over the X-Gene1. On a Memcached test, which makes use of that RoCE feature of Ethernet and with the transaction latency held at 30 milliseconds for 95 percent of the transactions (called TP95 in the lingo), the X-Gene2 is showing more than 2X performance compared to X-Gene1. And on the ApacheBench Web serving test, X-Gene2 has about a 25 percent performance advantage over its predecessor.
But this is not the competition. The Xeon E5 from Intel is. And Singh calculates that a rack of X-Gene2 systems will burn about 30 kilowatts and pack 6,480 threads running at 2.8 GHz. These nodes will have an aggregate of 50 TB of memory and 48 TB/sec of memory bandwidth and will be able to crunch through 750 million transactions per second on the Memcached test with 95 percent of the transactions coming in at under 40 milliseconds. A cluster of 80 two-socket machines based on Intel's Xeon E5-2630 v2 processors, with six cores and twelve threads per socket, delivers 1,920 threads and Singh estimates that such a cluster could deliver around 400 million transactions per second on the same Memcached test in the same power envelope of around 30 kilowatts. You could deploy twelve-core Xeon E5 processors in these nodes, of course, and do quite a bit more Memcached work, but such heftier Xeon nodes would consume considerably more power (about 60 percent based on raw TDP ratings) and possibly exceed the cooling and power capabilities of a single rack. These faster Xeons also cost a lot more – about twice as much. Applied Micro did not go so far as to offer a price/performance comparison here, and it is hard to guess what it might be. But suffice it to say that X-Gene chips have to have thermal, performance, and price advantages to get established in the market because of the pain of porting applications.
Roughly speaking, Singh says that for these kinds of bandwidth-intensive and cache-intensive workloads, the X-Gene1 can deliver the performance of an "Ivy Bridge" or "Haswell" Xeon E5, and that X-Gene2 will deliver even more performance in a much lower power envelope, particularly for latency-sensitive clustered applications. Many people will find this hard to believe, but eventually real-world customers will have their hands on X-Gene gear and real tests will be made to verify such claims. And Intel, of course, is not sitting still and will be moving on to its "Broadwell" Xeon family, including its own system-on-chip.
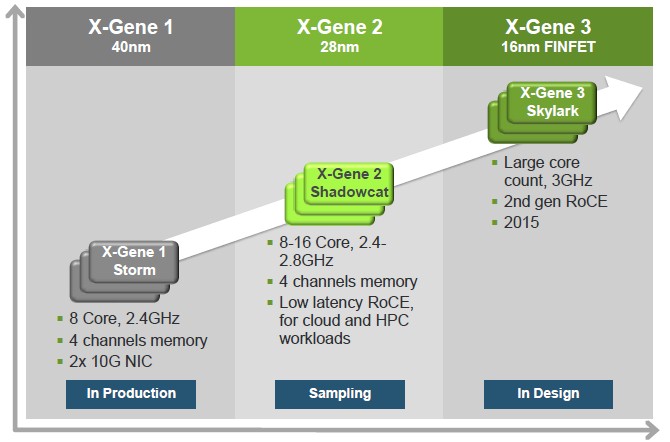
Further down the road, Applied Micro is readying its "Skylark" X-Gene3 processor for sampling in 2015. This chip will sport a third generation ARMv8 core designed by Applied Micro, with microarchitecture enhancements as well as a shift to TSMC's 16 nanometer FinFET 3D transistor technology. The chip will include a substantially upgraded on-chip coherent network and also inter-rack connectivity of some sort – Applied Micro is not being specific. The X-Gene3 SoC will have from 16 to 64 cores running at a baseline clock speed of 3 GHz. The power envelope will rise, given all of those cores, but the performance is going to go way up, too. Singh says that other server chip makers will be "the pipe cleaners" for the 16 nanometer FinFET process and by the time it is ready to do sampling around the middle of 2015 it will be a mature process with the kinks worked out.






