



Shared Memory Clusters: Observations On Processor Virtualization
In the preceding articles on Shared Memory Clusters, I have been making a distinction between truly distributed systems – those that must explicitly copy data between systems – and the SMC's extended NUMA-based systems, which allows any processor to access any memory in the cluster. You can think of the boundaries between the distributed systems as being "hard." No matter how fast the link between systems, data sharing can only be done via copying; software asks an asynchronously executing copy engine to copy the contents of data buffers from one system to another.
This hard boundary also defines another boundary, one between operating system instances; operating systems normally assume that any of its processors can access any of the OS' memory. Although some researchers are working to blur this boundary, you don't normally have operating systems spanning these hardware boundaries.
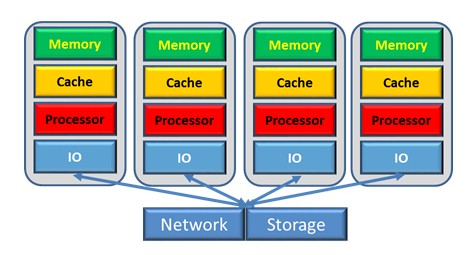
Processor virtualization starts by observing that a system – one where all processors can access all memory and all cache – can contain much more compute and memory capacity than is needed by any one operating system. Virtualization splits these hardware resources – ones normally thought as associated with a single operating system – amongst multiple operating systems. Each operating system is given some fraction of the system's processor cores – also presented as some fraction of the system's compute capacity – and some fraction of the memory available in that same system.
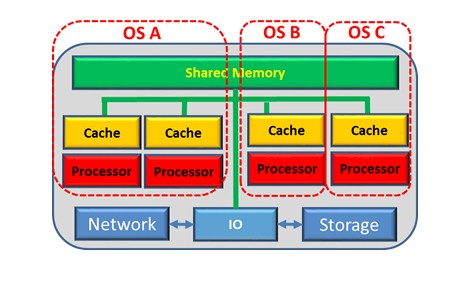
There is a boundary between OSes, but the only hard boundaries are that:
- The compute capacity used by all of a system's OSes is no more than the compute capacity of this single system, and
- The memory used by all of a system's OSes is no more than the memory available in that system.
Obvious enough, right? That lack of a hard boundary buys quite a bit of flexibility. If an OS needs more memory and it is available, that OS can have more memory. If an OS needs more compute capacity, it can often get it simply because the other OSes are not using it. Flexible, yes. But the natural logical division between OSes that is enforced by the hardware's boundary between distributed systems still exists even between the OSes sharing the same system. All the security advantages of that isolation are still there. Given an OS per system, the hardware of distributed systems guarantees no sharing between OSes.
Instead, with multiple OS instances per system, a software layer called a hypervisor enforces this isolation – this boundary - between OSes sharing the same system. Because of this hypervisor, firmware separate from the OSes, each OS can act as though it is alone on that system. Each OS can also be sure that the contents of its memory are not accessible from any other OS; the hypervisor assigns each OS its own memory and keeps the OSes separate. Although the memory is physically common, the hypervisor enforces data isolation for each OS. The hypervisor maintains a flexible boundary between OSes, which is a hard boundary in distributed systems.
So what does all of this mean to SMCs? At its most simple, am SMC is a lot of processors all with direct accessibility to a lot of memory. SMCs can be thought of as many SMPs with each SMP's many processors able to access into each other's memory. As you have seen, SMCs are like large multi-level NUMA-based systems. Because of the SMC's connection technology, these are the processors and the memory that would otherwise be found on multiple distributed systems. Rather than these processors having to ask a DMA copy engine to move data between these systems, the processors are able to access this otherwise distributed memory themselves.
So now let's factor in processor virtualization. With SMCs we have a lot of compute and memory capacity now also available to a lot of OSes. The hard boundary of distributed systems does not exist. Virtualized SMCs then is also a lot of flexibility. You need more memory? It's there. More compute capacity? It's there. More OSes? Sure, why not?
OK, now to drop the other shoe.
As was discussed in other articles of this series, SMCs use an extended form of a NUMA-based topology. (NUMA is short for Non-Uniform Memory Access where, from the point of view of some reference processor, some memory is more quickly accessed than other memory.) We also know that NUMA-based systems have been around for quite a few years. As to processor virtualization, the hypervisor assumed here is well aware of the system's NUMA topology. In order to provide each OS the best performance (i.e., the shortest time to access memory), the hypervisor when possible will attempt to allocate each processor of an operating system close to its memory.
For example, let's assume a system with multiple processor chips, each chip having, for example, eight processor cores and hundreds of gigabytes of memory, a basic simple NUMA-based system. If your OS happens to need only four processors and only tens of gigabytes of memory, the hypervisor will attempt to allocate your OS' memory and processor resources both from a single chip. As a result, the OS' processors will only be accessing memory local to that chip; because of this hypervisor design, the OS itself can remain unaware that it is part of a NUMA-based system.
Recall, though, that SMCs have multiple levels to its NUMA memory hierarchy. Restating them here:
- Local: A processor, making an access outside of its own cache, ideally finds its data in either memory directly attached to the processor chip or in the cache of processor cores on the same chip. (If in the chip's local cache, it tends not to matter where in the system memory the cached data block really came from.) In the figure below, the processor cores of Processor Chip A are local to the memory also attached to Processor Chip A.
- Remote: A Processor Core in Processor Chip A needing to access the data residing in the memory attached to Processor Chip B or the contents of cache in processor cores of that same chip is considered remote. Ideally, as shown here, this remote chip is directly attached to the reference processor's chip (i.e., one hop), but the access to the remote chip might require more than one hop. I tend to think of Remote access as taking 20 to 50 percent longer than a Local memory access, but twice as long is not unheard of.
- Far: Think of this type of access as being from the memory of a separate board (although reality might be different). The key concept here is that the memory accesses tend to be still longer. Largely to get your head around the concept, think of these as being roughly five times longer than a local access, although actual latencies vary widely around this number. A core on Chip B accessing the memory off of Chip M would be considered Far and also may take one hop (as shown here) or multiple hops; additional hops add access latency.
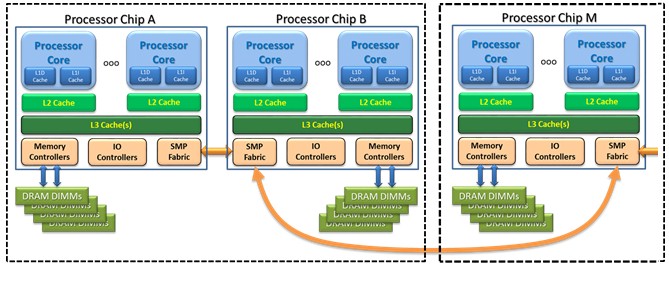
As it relates to the hypervisor, its job is to place an OS' processors as being Local if it can, on directly-attached chips if it needs to, and spanning more chip's cores and memory if it must. Again, the purpose is to generally minimize each OS' processor's memory access latencies.
When the hypervisor is unable to ensure complete locality for an OS, the OS itself must manage the fact that it is then part of a NUMA system. The OS might find that:
- For each set of processor cores, each set on different chips, there is some amount of the OS' memory Local to those cores. From the point of view of each chip's set of cores, all other memory is considered Remote or Far. The basic rules for NUMA management within an OS call for each thread's memory to be allocated from the chip whose cores are considered most preferred by that thread.
- Some amount of the OS' memory is Remote or Far from all of the OS' cores. This memory gets used but it may be less preferred than Local memory.
- Some number of the OS' cores have no Local memory. No thread prefers to be dispatched to these. Not good, but as we will see next, not necessarily bad either.
Cache Topology
As a variation on this theme, take another look at the preceding figure; each chip not only has multiple cores but also multiple caches. Normal cache coherency in an SMP allows – actually, requires – your processor to be able to access data from the cache of another processor if your needed data happens to be there, especially if that processor is on the same chip. Such an access from a Local core's cache is relatively fast; it is slower than an access from the core's own cache, but typically quite a bit faster than from the attached memory. Once a data block is in a processor's cache, it also does not matter much whether that data block was originally in Local, Remote, or Far memory, since the cached data block now gets accessed at Local cache speeds.
In a sense, this local cache adds another level of the NUMA storage hierarchy (i.e., Local cache, Local Memory, Remote Memory, and then Far memory, ordered by access latency). Whether that block of data had been from Local, Remote, or Far memory originally, if that data block resides now in a local core's cache, that data can be accessed very quickly from there.
Now, with that in mind, recall the placement of an OS' processor cores and memory as discussed above. It was often a good idea to place an OS' processors wherever the OS has memory and vice versa. With this model, the OS itself finds its processors spanning multiple chips and so attempts to manage the NUMA topology it finds; again, the OS attempts to place each task's data close to the core(s) on which the tasks would prefer to execute.
In the following figure, as an example, even though each of the chips might have, for example, eight cores, an eight-core OS A might finds itself with four cores on each of two chips due to the OS A's memory needs. Keeping the cache state coherent can often mean that a core must ask the other chip "does your cache have the data that I need?" This takes a little longer, and if in a Far chip's cache, quite a bit longer. (Another article in this series discusses this further.)
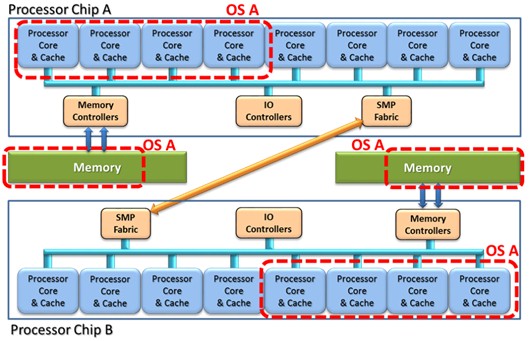
Although it may make sense to distribute an OS processor wherever the OS also has memory, there is also value in keeping the processors – or really their caches – close to each other. If a core's caches under control of an operating system instance are only on a single chip, it is only the caches on that chip that need to be asked "Do you have my data?" If so, the answer will always be a local core's cache that will have the data and do so quickly. For example, let's take that same OS' capacity and memory needs as outlined above, place the eight cores on a single chip, and allow its memory to exist as Local, Remote, and Far memory as in the following figure.
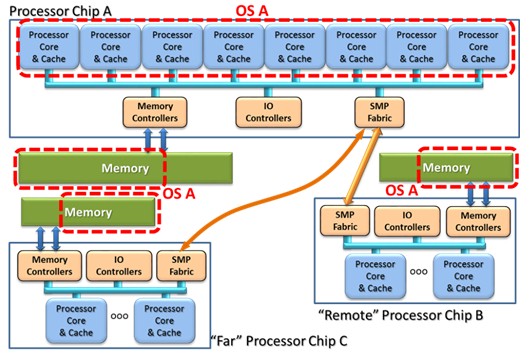
By placing the cores associated with an operating system instance on just the one chip, all of that OS' accesses from cache are also then Local cache accesses. The OS the perceives its preferred memory as being that portion which is Local to all of the processor cores, but would also use Remote or even Far memory based on paging performance statistics. This may be preferred by your application, but either placement might be fine.
Operating Systems Sharing Memory
Changing gears, I have so far spoken of each OS as being able to access only its own memory, no matter its location in SMC's NUMA topology. Further, no matter the number of OSes sharing the same physical memory, we've kept the OSes isolated from each other. And, as with truly distributed systems, data is explicitly copied from the memory of one OS into the memory of another even though the physical memory is common; we have effectively assumed that normal networking mechanisms are being used for OSes – and processes in these OSes – to communicate with each other. That assumption fell out of the requirement that we stated earlier that OSes are completely isolated from each other by the hypervisor. That isolation still remains a good concept to maintain for most uses.
Unlike truly distributed systems, with SMCs any processor is capable of accessing memory throughout the cluster. With SMCs, the boundary between systems is mostly performance-related, not the functional limit inherent in distributed systems. The boundary between OSes maintained by the hypervisor is a software, not a hardware, limit. So we have the option of allowing OSes to access the memory otherwise owned by another. This, in turn, enables some forms of data sharing.
Before I go on, allow me to outline a metaphor for what we will be discussing next. If you have taken upper-level computer science classes, you are well aware of the notion of a process and its notion of process-local storage. In this, each process has its own private address space. The OS ensures a strong level of isolation between these processes merely by ensuring that at any moment in time each process' own addresses are mapped to only its own pages in physical memory. Unless the processes request otherwise, each process can act as though it is the only process in the whole of the OS and Process A is ensured that Process B can't see Process A's data. Are you beginning to feel the similarity to our virtualization discussion?
Processes within an OS can communicate if they desire to do so; one mechanism for doing so is via shared memory moderated via the OS. Multiple processes are essentially asking the OS to map a portion of their own otherwise separate address space onto the same pages of data; this address mapping allows the processes to directly share the same data without copying. The data may well be seen at different addresses by the processes, but it really is the same data and in the same physical location in memory. A Process A, having made some data addressable within its OS – perhaps with this data residing in physical memory – is giving a Process B the right to access that same data. The remainder of Process A's data remains private to Process A.
In order to explain a bit further, in order to allow me to map this metaphor onto SMCs, let's take a look at the relatively simpler addressing model used by the Power processor architecture. In that architecture, each process has its own effective address space; for our purposes, the effective address space is 64 bits in size (i.e., 264 bytes = 16 giga-gigabyte = 16 pebibytes). Processes sharing data have the OS map their own process-local effective address onto an OS-wide common virtual address. Memory virtualization is enabled by having the hypervisor map this virtual address onto a real address (i.e., a physical location in memory). The processor hardware is aware of these mappings; each memory access done by a program executing on a processor has the process' effective address translated ultimately to a physical memory location.
Now picture the OSes of a SMC as each having their own memory, wherever the memory might really reside. As mentioned earlier, each is normally private to this OS with the hypervisor enforcing this isolation. As with inter-process memory sharing, we now also want to directly share data between some OSes. To do so the OSes are going to request the creation of a window in physical memory common between these sharing OSes.
Let's have OS A make a request of OS B via networking communication to share a block of data in memory. One – perhaps both – informs the hypervisor that it is willing to use some portion of its memory for multi-OS sharing. Both OSes suggest to the hypervisor a portion of their own virtual address space to be mapped by the hypervisor onto this common shared memory window. In this addressing model, each OS perceives that shared data as residing in its own address space, but ultimately, only the hypervisor knows where in physical memory the shared memory really resides.
Comparing this back to our process-level shared memory metaphor, suppose that what we really wanted to have happen is that two processes, now each on a different OS, want to use shared memory in which to communicate. Process A of OS A and Process B of OS B decide to share a common buffer of some size. One process, Process A of OS A, requests of OS A the allocation of an address space, ultimately having that mapped by the hypervisor onto some part OS A's physical memory. Process B of OS B allocates some effective/virtual address space for the purpose of sharing this buffer. Both OSes tell the hypervisor of their intent, with the result being that each effective/virtual address range for each process and OS is mapped onto the same physical memory pages. We see this in the following figure with the shared memory have been allocated out of the physical memory otherwise associated with OS A.
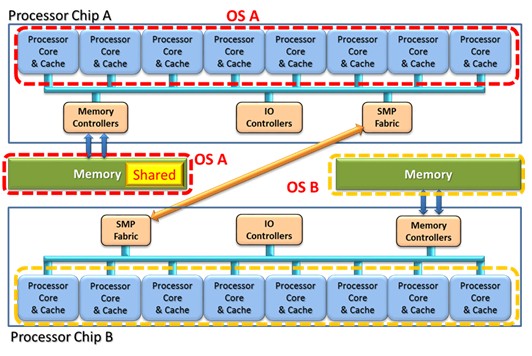
So far this is just two processes of two OSes sharing the same physical memory. This could potentially be done within any cache-coherent SMP. What SMC adds to this notion is a potentially huge number of OSes that might be willing to do this (instead of using networking-based communications) as well as the potentially longer storage access latency involved if the processes are relatively far from each other.
As a conclusion on this section, some SMC vendors tend to present SMCs as being easy to use because the entire complex is supported by a single OS. Given full SMP-like access from all processors (i.e., all memory is accessible from all processors and all cache is coherently maintained), this perception is not unreasonable. If, though, your preference is to use multiple OSes, perhaps because of availability, security, or other functional reasons, it is feasible – but perhaps not available today – to use the memory otherwise associated with multiple OSes for an application's memory and processing needs.
Articles In This Series:
Shared Memory Clusters: Of NUMA And Cache Latencies
Shared Memory Clusters: Observations On Capacity And Response Time
After degrees in physics and electrical engineering, a number of pre-PowerPC processor development projects, a short stint in Japan on IBM's first Japanese personal computer, a tour through the OS/400 and IBM i operating system, compiler, and cluster development, and a rather long stay in Power Systems performance that allowed him to play with architecture and performance at a lot of levels – all told about 35 years and a lot of development processes with IBM – Mark Funk entered academia to teach computer science. [And to write sentences like that, which even make TPM smirk.]He is currently professor of computer science at Winona State University. If there is one thing – no, two things – that this has taught Funk, they are that the best projects and products start with a clear understanding of the concepts involved and the best way to solve performance problems is to teach others what it takes to do it. It is the sufficient understanding of those concepts – and more importantly what you can do with them in today's products – that he will endeavor to share.






