



Xeon Phi To Get 3X Speed Bump, Omni Scale Fabric

Intel is showing off a few more of the feeds and speeds of its forthcoming "Knights Landing" Xeon Phi chips and talking a bit about the future network fabric that will be paired with these compute engines as well as its flagship Xeon processors.
The current "Knights Corner" parallel X86 processor has up to 61 Pentium-style P54C cores implemented on a die and is available only as a PCI-Express 2.0 coprocessor, plugging into a system much like a graphics card or GPU accelerator does. These coprocessors are being adopted to accelerate parallel workloads in financial services and in various kinds of simulation. Their uptake could expand considerably once the future "Knights Landing" Xeon Phi chips come out.
The Knights Landing chips have been in development for a few years now, and with them Intel is going one step further and making the Xeon Phi available as a standalone processor in its own socket as well as in a separate card that links with server processors through PCI-Express 3.0 links. Intel revealed that information about Knights Landing back at the International Super Computer 2013 conference in Leipzig, Germany a year ago, along with the fact that Knights Landing would be etched in its 14 nanometer processes and would have on-package memory that would boost the memory bandwidth. At the SuperComputing 2013 conference last fall, Intel divulged that the Knight Landing chip would be surrounded by high-bandwidth, in-package memory for very fast memory access for the many cores on the die – what it called near memory – as well as DDR memory linked to the chip on the same printed circuit board – what it called far memory. Shortly thereafter, Intel said that it would include ports for future interconnect fabrics on both the Xeon and Xeon Phi chips.
Ahead of ISC'14 this week, where Rajeeb Hazra, a vice president in Intel's Data Center Group and general manager of its Technical Computing Group, is doing the keynote, Intel let a few more details out about the Knight Landing chip. Charles Wuischpard, who used to run system maker Penguin Computing and who is now vice president and general manager of the Workstations and High Performance Computing unit in the Data Center Group, walked through the new details of the system.

We now know a few more things about Knights Landing, and we also see why Intel has been putting out information in bits and pieces for so long. The latest specs on the Knights Landing chip confirm some of the rumors that were going around late last year about the device, which we now know will ship in commercial systems sometime in the second half of 2015.
The Knights Landing chip will be based on a modified variant of the "Silvermont" Atom core, which among other things is used in the eight-core "Avoton" C2000 processor. These low-power cores will have four threads per core, just like the modified Pentium P54C cores in the original Xeon Phi had. The modified Silvermont core will also include 512-bit AVX vector math units. Intel is not being specific about the number of cores that will be on the Knights Landing die, but Wuischpard did say that it will have at least as many cores as the current Knights Corner Xeon Phi chip. If you look into the details, Intel also adds that the cores in the Knights Landing chip will be compatible with the "Haswell" Xeon instruction set, with the exception of the TSX transactional memory feature.
The clock speed on the Knights Landing chip was not revealed, either, but Wuischpard said that the Knights Landing chip would have more than 3 teraflops of peak theoretical double-precision floating point math capability, which is about three times the oomph of the Knights Corner coprocessor it replaces. Given that Knights Corner was implemented in 22 nanometer processes and Knights Landing will be etched in 14 nanometer processes, and that clock speed increases really increase the heat, it is reasonable to expect that most of the performance gains will come through radically improved cores, more of them, slightly higher clock speeds, and the memory bandwidth that comes from that memory on the Knights Landing package.
Intel says that it will have at least 16 GB of that near memory close to the Silvermont cores on the Knights Landing chip package, and that this will offer at least five times the bandwidth of DDR4 main memory that is on the circuit board but not on the package.
"It turns out that one of the choke points in many applications used today is I/O and memory bandwidth, and this is specifically designed to remove that bottleneck."
This "ultra high bandwidth" memory is being jointly developed by Intel and memory maker Micron Technology, and Wuischpard would not comment if this memory was based on Hybrid Memory Cube stacked memory. Micron confirmed in a separate announcement that the on-package memory is derived from the technology used in HMC Gen2 memory. Intel and Micron say that this on-package memory takes up one third of the space and is five times as power efficient as GDDR5 graphics memory used in Xeon Phi and GPU accelerators, and takes one half the energy per bit as DDR4 memory and does so in half the physical space.
The Silvermont cores will no doubt have their own layers of cache memory to keep the data being staged from far and near memory and down into the cores. The specs for that cache have not been announced. Intel has not revealed the maximum DDR4 memory capacity supported on the Knights Landing, but does say in a statement that the chip will "support DDR4 system memory comparable in capacity and bandwidth to Intel Xeon processor-based platforms, enabling applications that have a much larger memory footprint."
Intel plans to offer the Knights Landing Xeon Phi processor on a PCI-Express adapter card as well as for a standalone processor in a socket of its own inside of a system. It is not clear which one will come first, or if they will both be launched at the same time.
The other big announcement at ISC'14 this week in Germany is that the Xeon Phi chips will include ports for Intel's future Omni Scale fabric.
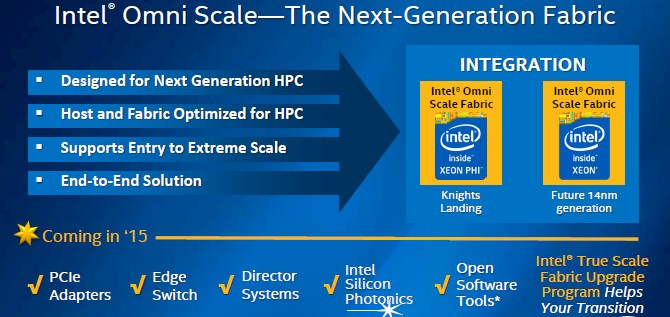
Intel is not providing a lot of information about the future Omni Fabric, but Wuischpard said that it was not InfiniBand as we know it and that it was not the "Aries" dragonfly interconnect that Intel bought from Cray a few years ago, either.
Wuischpard said that Omni Scale "retained some of the flavor" of the prior generation True Scale, but "is really distinctive in that it is a non-InfiniBand solution."
Intel has made its own Ethernet network adapters for many years, and it bought Fulcrum Microsystems for its Ethernet switching ASICs and QLogic for its True Scale InfiniBand switch and adapter chips. The Cray Aries interconnect – and importantly, the engineering team that created it – was icing on the cake. And Omni Scale, as the name suggests, is leveraging technology Intel acquired from Cray and QLogic as well as its own networking know-how to create the Omni Scale fabric. Whatever it is, Omni Scale will look enough like True Scale QDR InfiniBand for applications coded for the latter to be compatible with the former. Intel will also provide a full set of open source software tools for Omni Scale.
"Over the last four months, our business with True Scale has done tremendously well," Wuischpard. "We think that based on publicly available information we have been gaining share in the market. In part this is because our customers want to get to Omni Scale and we are providing an upgrade path."
Throughout 2015, Intel will roll out PCI-Express host adapter cards supporting Omni Fabric networking, and it will also make edge switches and large director switches to lash nodes and networks together. Intel will also have silicon photonics cables and connectors that support Omni Fabric, and it is reasonable to assume that such ports will in fact first appear on the Knights Landing chips.
The neat thing about the future Knights Landing chip is that with the main memory (both the unspecified near memory and the DDR4 far memory) and the network ports on the chip, the Xeon Phi is a standalone, self-contained unit of compute, ready to be plugged together into clusters. And that, presumably, is precisely what many enterprises and supercomputing centers will want to do for running workloads.






