



OpenStack Dominated By Tire Kickers, Code Testers – For Now
There is no question that OpenStack has momentum behind it and that organizations of all types and stripes are thinking about how they might deploy the open source tool as the main control plane for their infrastructure. OpenStack has lots of mindshare, but it has yet to become a normal tool in use among large enterprises. But there are many who are working to make this happen, and many more believe it will happen.
It is hard to remember sometimes that OpenStack is not yet four years old and arguably has only been a mature product for about 12 to 18 months, depending on where you want to draw the line. These things take time, and if you look at the adoption curves, size of the community, and the scope of the projects affiliated with Linux as a gauge, then OpenStack is growing faster than Linux did as a force in datacenters. The reason is simple enough: Linux made open source software safe, and along with it a slew of database, middleware, and application development tools. OpenStack stands on the shoulders of Linux, just like every hyperscale datacenter operator (except Microsoft with Azure) and most Internet startups do these days.
At the OpenStack Summit this week in Atlanta, the OpenStack Foundation trotted out companies like Wells Fargo Bank, AT&T, Walt Disney Company, Digital Film Tree, Sony, PayPal/eBay, and others to talk about how they had or will eventually deploy OpenStack in their infrastructure. In just about every case with a big company, the techies at the big public companies are able to talk about some of the tricks they have learned in running OpenStack or very generally about how they might fit it into their business, but they are not allowed to talk about the actual specifics of how they are using OpenStack. This is just the nature of public relations at public companies. (You can see an official list of OpenStack users at this link.)
That said, the OpenStack community cannot drive features and functions into releases of the software if they don't get a sense of how companies are deploying the software and how they are meshing it into their infrastructure. So for the past couple of releases, the OpenStack Foundation that controls the open source project has done a survey of the customer base. JC Martin of eBay, Ryan Lane formerly of Wikimedia (he has just joined a startup called Lyft), and Tim Bell of CERN have managed the gathering and anonymizing of the data from the community surveys.
The results of the latest survey were revealed at the summit, and they show that the base is still dominated by proofs of concept and test/development clouds – in this case very much like the early days of server virtualization on X86 machinery, which started to gain traction a decade ago and has absolutely become normal today. That doesn't mean that OpenStack doesn't have some very large installations. It certainly does, with the largest being Rackspace Hosting, which co-founded the project with NASA in July 2010 after catching the open source bug as a means to get some help on building a control system for its hosting and cloud operations. There are more production systems than in years gone by for sure, and there will be more, but the uptake is a lot slower than many in the community – especially the vendors who are trying to make a living selling support for OpenStack or wrapping up OpenStack into a broader or deeper product.
In the most recent survey, which coincides with the beginning of development on the "Juno" release of OpenStack scheduled for this fall, 1,780 people responded to the survey, covering a total of 506 OpenStack deployments. The United States and Canada accounted for 195 of the OpenStack clouds, with Europe having 143 and Asia having 107. Across all of those sites, there are 210 development/test clouds, 218 proofs of concept clouds, and 209 production clouds that are managing real workloads.
This is obviously not all of OpenStack clouds in production in the world. Earlier this week, Radhesh Balakrishnan, general manager of virtualization and OpenStack at Red Hat, told EnterpriseTech earlier this week that the company had a “healthy double digit number” of users in production with its implementation of OpenStack, which has only been out since last July, and said further that it has proofs of concept that measure in the “three digits.” Canonical has had OpenStack embedded in Ubuntu Server since the 11.04 release three years ago, and Mark Shuttleworth, the founder of the Ubuntu Linux project told us at the OpenStack Summit that Canonical had an order of magnitude more production and PoCs than Red Hat. As you will see from the survey results, Ubuntu Server is by far the most popular Linux deployed underneath OpenStack. Part of that is being early, and part of that is creating the automation to more easily deploy and manage an OpenStack cloud.
Our guess is that there are probably many thousands of proofs of concept OpenStack clouds out there, and perhaps as many as a thousand production clouds. It is hard to say, and given the open source nature of OpenStack and the dozens of ways to consume it, no one really knows for sure. By the way, the thousands of production OpenStack clouds is on the same order of magnitude as the number of large-scale supercomputer clusters and production-grade Hadoop clusters installed globally.
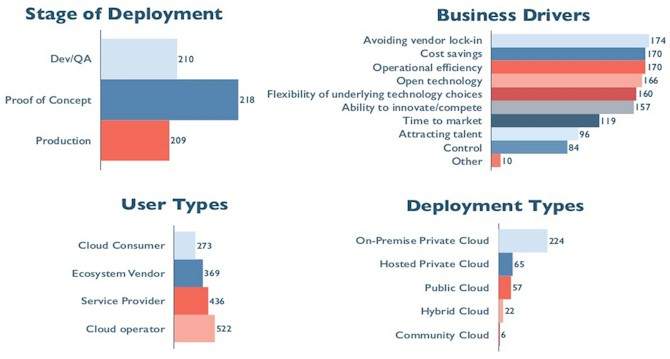
As is the case with the adoption of any open source software, avoiding vendor lock in, saving money, increasing operational efficiency and adhering to open standards are the main business drivers for production OpenStack systems, as you can see from the chart above.
Generally speaking, explained Lane, the production OpenStack clouds are a bit larger than the test/development clouds and both are quite a bit larger than proof of concept clouds using the software. Of course, size is relative to the business (meaning the compute and storage workload) and the size of the company (in terms of users and revenues), so generalizing is not necessarily useful. What is a large cloud to a small company is a small cloud to a large company. Production clouds also tend to have an older vintage of OpenStack running on them, and some of that has to do with the fact that rolling upgrades are not yet available for the elements of the OpenStack cluster. The community is working on it, but this is not a trivial matter.
The production clouds are still not very large, based on the data the OpenStack Foundation has gathered, but you have to take that with a grain of salt because even though the people handling the survey do not give anyone access to the raw data and do everything they can to keep the data anonymous - including not allowing queries that cross datasets that might allow someone to identify a cloud in the mix of data - still some companies choose not to provide information for specific things.
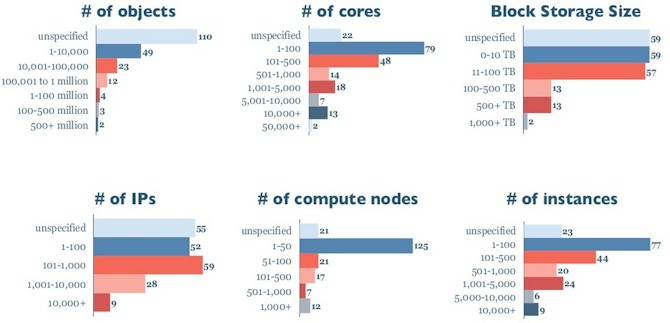
The vast majority of production clouds have fewer than 50 nodes and fewer than 100 cores, but as you can see from the data, there are also some production OpenStack clouds that have hundreds to thousands of nodes and from thousands to tens of thousands of cores. If you ignore those customers who were not using object storage or who didn't want to divulge details, then the majority of OpenStack clouds in production have fewer than 100,000 objects at the moment. But there are a handful of clouds that have hundreds of millions of objects. As for block storage, the same holds true. Most of the production clouds have less than 100 TB of block storage capacity, but there are some that have pushed up into the petabyte territory.
As you might expect, OpenStack shops like the Puppet and Chef configuration management tools that are the ones of choice for the hyperscale datacenter operators, but they also have a number of other tools they deploy to help setup their OpenStack clouds:
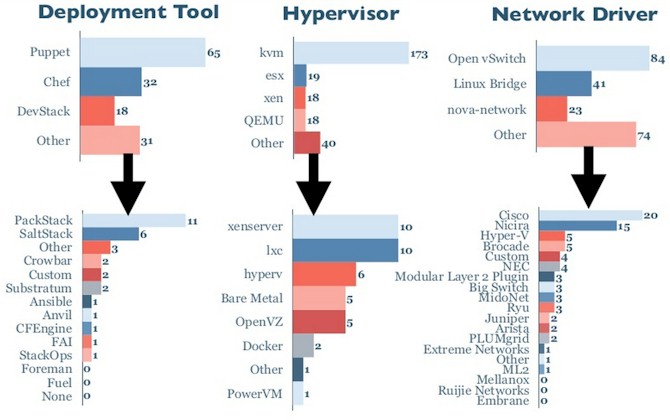
When it comes to hypervisors, KVM, which is most often associated with OpenStack and a pairing that both Canonical and Red Hat promote for their respective Linux-OpenStack combinations, is the most popular of the many options. Interestingly, VMware's ESXi, LXC containers, and Docker containers are all more popular among proofs of concept clouds than on production clouds, and this may be an indicator of things to come. Time and again at the summit, companies talked about how they wanted to use OpenStack to manage physical and virtual machines of all types and flavors. So in the long run, for instance, companies could decide to keep ESXi and not use VMware's vCloud. This would save them the virtual machine conversion grief, and very likely some money. Ditto for Microsoft's Hyper-V, which can also be controlled by OpenStack. In shops that have all three key hypervisors – a likely scenario at large enterprises that have their Linux and Windows application developers in their own silos. Or rather, they used to until a mixed environment like OpenStack comes along.
There is a wide variety of network drivers that are being used to glue hypervisors to OpenStack as well, with Open vSwitch being the most popular and, again, the one most commonly associated with OpenStack these days. But the diversity in the network is a lot higher than in the hypervisor on production clouds.
Believe it or not, someone in production is claiming to have the original Austin release of OpenStack running, something that Lane said he himself did not believe. There are still a handful running on the subsequent three releases – code-named Bexar, Cactus, and Diablo. Essex, arguably the first usable release, was still on 61 clouds, and Folsom, the second release of 2012, is on 64 machines, and the Grizzly release, when OpenStack really started to get some traction a year ago, is on 84 machines. The Havana release from last fall is on 42 clouds, and the latest Icehouse release from a month ago is already on five clouds. Interestingly, there are 26 clouds that pull right off of the trunk code as it is updated and do not wait for releases.

There is one other interesting thing that came out of the most recent OpenStack survey is that there are still some customers who are making use of APIs that make OpenStack compatible with the EC2 compute and S3 object storage at Amazon Web Services. To be specific, that's 87 clouds with EC2 APIs and 54 clouds with S3 APIs. There are a few that are using the Open Cloud Computing Interface (OCCI) APIs, and none have yet adopted the APIs for Google Compute Engine.
One of the reasons why Citrix Systems left the OpenStack effort back in the early days, bought Cloud.com, and open sourced CloudStack as an Apache project was that Rackspace was insistent that having AWS compatibility was not going something that OpenStack should worry about it. There are those, it would seem, who agree with Citrix and Eucalyptus Systems, whose eponymous cloud controller seeks to clone as many of the AWS services as it can for a relatively small startup. OpenStack decided to seek its own path and do things its own way, which certainly has its merits. But AWS compatibility is not something that many enterprises can ignore.






