



Google Lifts Veil On “Andromeda” Virtual Networking

The biggest public cloud providers have adjacent businesses that actually fund the development of the infrastructure that starts out in their own operations and eventually makes its way into their public cloud. So it is with Google's "Andromeda" software-defined networking stack, which the company was showing off because it is, after all, Interop this week.
The Andromeda network virtualization stack is part of the Google network, which includes a vast content distribution network that spans the globe as well as an OpenFlow-derived wide area network that has similarly been virtualized and which also spans the globe. Amin Vahdat, distinguished engineer and technical lead for networking at Google, revealed in a blog post that after using the Andromeda SDN stack internally on Google's homegrown switches, servers, and storage that it has been adopted as the underpinning of the Cloud Platform public cloud services such as Compute Engine (infrastructure) and App Engine (platform). The news was that Andromeda was the default networking stack in two of the several Cloud Platform regions – us-central1-b and europe-west1-a – and that the company was working to roll it out into the other regions as fast as was practical to make its own life easier and to give customers higher-performing networking for their cloudy infrastructure.
A month ago, at the Open Network Summit, Vahdat gave the keynote address, and he talked quite a bit more about Andromeda than in the blog post and explained how it related to the global network at Google. But before all that, he also explained why it was important to have virtualized, high-bandwidth, low-latency networking available for workloads, and cautioned everyone that the introduction of new technologies that push scale up or out always cause issues. Even at Google, which has no shortage of uber-smart techies.
"In the cloud, you can gain access to the latest hardware infrastructure, at scale and with the expertise to make it work," explained Vahdat. "So I think this is key. Any time you go from 1 Gb/sec to 10 Gb/sec to 40 Gb/sec to 100 Gb/sec, or from disk to flash to phase change memory or whatever your favorite next generation storage infrastructure is, things are going to break. Basically, there are going to be assumptions built throughout your infrastructure that will make it impossible to leverage that new technology. So, you will put in your 40 Gb/sec network, and nothing goes any faster. And in fact, maybe it goes slower. You put in your flash infrastructure, and nothing goes any faster. It takes a huge amount of work to leverage this new technology, and in the cloud you have the opportunity to do it once and reap the benefits across many, many services and customers."
In short, Vahdat says that companies will be attracted to cloud computing because of the on-demand access to compute and storage and utility pricing, but they will stay for a lot of other reasons, chief among them the virtualized networks and related services to monitor, manage, protect, and isolate the links between servers, storage, and the outside world.
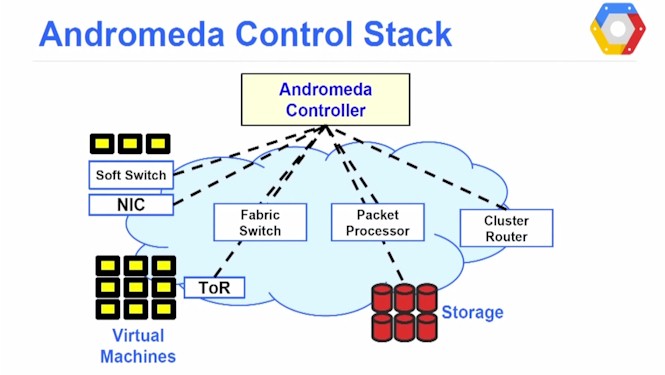
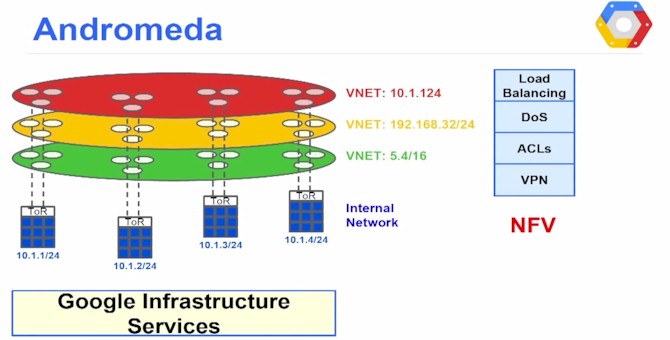
By his own definition, software-defined networking means splitting the control plane of the network from the data plane, which allows the independent evolution of both parts of the network stack. By doing so, you can put the control plane on commodity servers (as many networking vendors are starting to do with OpenFlow and other protocols) and use other gear in the data plane. In Google's case, explained Vahdat, Andromeda splits the network virtualization functions between these soft switches above and fabric switches and commodity packet processors that shift the bits around the network.
Andromeda also hooks into cluster routers that link networks to each other within a datacenter or into the B4 wide area network that connects Google's region's together into what is, in effect, a massive virtual Layer 2 network with all of its 1 million plus servers attached. (Yes, Google did this several years ahead of the rest of the IT industry, as it often does with technologies. Those who scale break things first and therefore have to fix things first.)
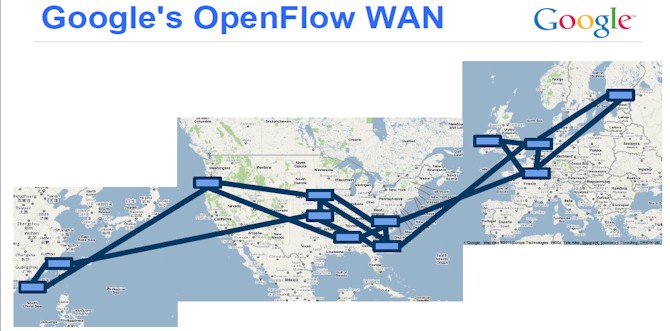
The B4 WAN is based on homemade routers that have hundreds of ports running at 10 Gb/sec speeds (one of them is shown in the image at the top of this story); they are based on merchant silicon (Google does not say which ASICs it is using) and presumably an X86 processor as well and run Google's own tweaked version of Linux that has been hardened for use in network gear. These G-Scale switches use the open source Quagga BGP stack for WAN connectivity, and have ISIS/IBGP for linking internally to the networks inside Google's datacenters. They have support for the OpenFlow protocol as well. The G-Scale machines have hardware fault tolerance and have multiple terabits per second of switching bandwidth. The WAN has two backbones: the outward facing one that links into the Internet and content distribution networks and the internal one that is used for Google's own workloads, which includes a slew of things aside from its search engine and Cloud Platform.
Google has done away with a slew of boxes in the middle that provide load balancing, access control, firewalls, network address translation, denial of service attack mitigation, and other services. All of this specialized hardware complicates the topology of the network, said Vahdat, and it also makes maintenance and monitoring of the network difficult. Importantly, storage is not something that hangs off a server in the Google network, but is rather a service that is exposed as storage right on the network itself, and systems at any Google region can access it over the LAN or WAN links. (Well, if they have permission, that is.)
Like many of the massive services that Google has created, the Andromeda network has centralized control. By the way, so did the Google File System and the MapReduce scheduler that gave rise to Hadoop when it was mimicked, so did the BigTable NoSQL data store that has spawned a number of quasi-clones, and even the B4 WAN and the Spanner distributed file system that have yet to be cloned.
"What we have seen is that a logically centralized, hierarchical control plane with a peer-to-peer data plane beats full decentralization," explained Vahdat in his keynote. "All of these flew in the face of conventional wisdom," he continued, referring to all of those projects above, and added that everyone was shocked back in 2002 that Google would, for instance, build a large-scale storage system like GFS with centralized control. "We are actually pretty confident in the design pattern at this point. We can build a fundamentally more efficient system by prudently leveraging centralization rather than trying to manage things in a peer-to-peer, decentralized manner."
Having talked about the theory of network virtualization and SDN, Vahdat explained in a very concrete way why virtualizing the network along with compute and storage was key, particularly for Cloud Platform, which will have workloads that Google cannot control or predict so easily.
Not too far in the future, this is what the underpinnings of a cloud is going to look like:
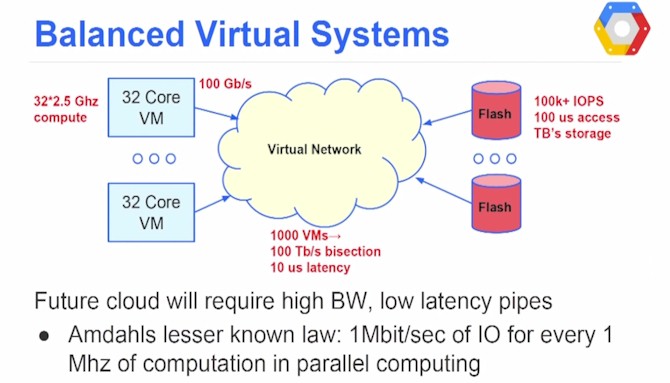
A compute node with two sockets will have 32 cores running at around 2.5 GHz or so, and using the other Amdahl Law – you should have 1 Mb/sec of I/O bandwidth for every 1 MHz of computation for a balanced system, that puts you on the order of 100 Gb/sec coming out of that server node. The storage disaggregated from the server will be terabytes of flash, with 100,000s of I/O operations per second and 100 microseconds of access time. A cluster will have perhaps 1,000 virtual machines and to get balance between the systems and the storage, that means you will need a virtual network between them that delivers around 100 Tb/sec of bisection bandwidth and 10 microseconds of latency. Moreover, these bandwidth needs will change as the workloads on the systems change – they may be more or less intensive when it comes to CPU, memory, storage, or I/O capacities.
"We are going to need a fundamental transformation in virtual networking," Vahdat explained. "We are going to need 10X more bandwidth, 10X lower latency, 10X faster provisioning, and 10X the flexibility in being able to program the infrastructure to support such a programming model."
Now you know why Google has long since taken control of its infrastructure, from every piece of hardware on up to the most abstract layers of software. It is always facing such scalability issues, and it has to squeeze out all the performance it can to stay ahead of the competition.
So how does Andromeda perform? Pretty well, according to Google's own benchmark tests. The blog doesn't have very much performance data, but the presentation from the Open Network Summit has a bit more. Before Andromeda was rolled out, Google had an earlier rendition of SDN with network function virtualization, which Vahdat said was roughly equivalent to the state-of-the-art available commercially today from network vendors. After analyzing these numbers, you might be wishing Google would sell you Andromeda and a stack of its IT gear. Here is how network performance stacks up at Google:
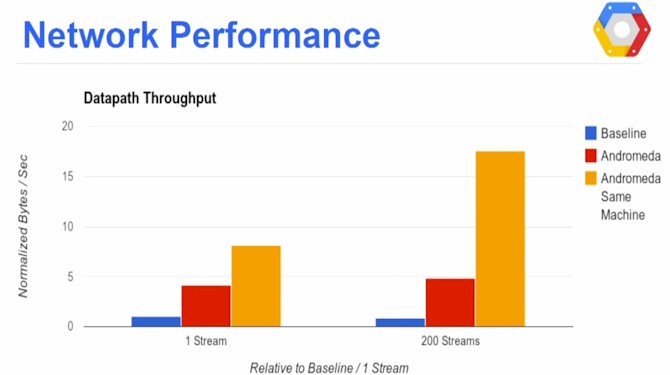
In this chart, the network stack performance transmitted between two virtual machines on Cloud Platform is shown for three scenarios. The blue bar is for the pre-Andromeda SDN/NFV setup, and it shows a relatively modest datapath throughput between virtual machines on distinct servers on one TCP stream. The Andromeda network stack is shown in red, and the gold bars show what happens when Andromeda is transmitting data between virtual machines on the same host. Vahdat says that Google will be trying to close the gap between the red and gold bars. If you run more TCP streams between the VMs, Andromeda actually does quite a bit better, as you can see. So it scales well.
Raw speed is interesting of course, but if attaining it eats up all of the CPU capacity in the box, then no work gets done by the server. So Google is also measuring how much CPU the Andromeda stack chews up. Take a look:
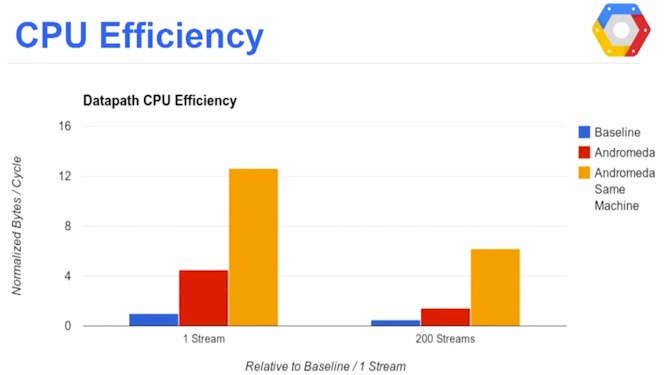
To express this, the Google benchmarks normalize against the pre-Andromeda network stack and show how many bytes per CPU cycle can be pushed. In this case, as you can see, Andromeda does roughly five times the compute per cycle as its predecessor. You can also see that adding TCP streams to the test eats into the CPU capacity, but that is to be expected. Shifting bits is not free.
The question now, as always, is what Google's revelations will have on the industry at large. Much of the software that Google started with is based on open source code, but it has been tailored so tightly to Google's homegrown hardware and software that putting out a set of APIs or even source code would probably not be all that helpful. (Unless you were competing with Google, of course.) The kernel data path extensions that Google has come up with as part of Andromeda have been contributed to the Linux community, so that is something.
No matter what, Google has shown very clearly what the practical benefits of SDN are and now large enterprises will be more comfortable wading in – perhaps starting first by firing up instances on Compute Engine and App Engine to run their some of their applications.






