



IBM Juices Hadoop With Java On Tesla GPUs
Commercial applications written in Java have plenty of parallel tasks that can be accelerated through the use of GPU coprocessors. IBM is very keen on leveraging the combination of its Power processors, which have high memory and I/O bandwidth, and Tesla GPU coprocessors from Nvidia, which have lots of cores and high memory bandwidth as well, to gain back some market share from X86 systems. The software stack for the Power-Tesla combo, and at the GPU Technical Conference last week in San Jose, IBM showed off a prototype Hadoop setup that got a significant performance speedup from running portions of its code on Tesla engines.
IBM also used the opportunity to talk up its OpenPower Foundation and its partnership with Nvidia to develop CUDA application development tools that are compatible with IBM's Power processors, laying out how they will work and when customers can expect to get their hands on them.
The Hadoop benchmark test is interesting in that it is yet another example where Big Blue has shown that Java applications can be significantly accelerated by GPUs. This gives enterprises a taste of things to come when Big Blue implements the features of the new Java 8 stack, which was revealed last week, and the forthcoming Java 9, due perhaps in 2015 based on AMD's roadmaps or 2016 based on what others have said, in its future homegrown Java virtual machine. As EnterpriseTech has previously reported, Oracle is teaming with AMD to integrate GPU acceleration into the Java stack for AMD's graphics chips.
Last September, at the JavaOne developer event hosted by Oracle, John Duimovich, a distinguished engineer at IBM and its Java CTO, said that IBM was happy with the Project Sumatra effort to make Java a peer to Fortran, C, C++, and Python in terms of offloading code from CPUs to GPUs. But Duimovich added that in the meantime, ahead of the inclusion of Project Sumatra in Java 9, there were things that could be done to put GPUs to use speeding up Java applications. To illustrate the point, he showed a sorting benchmark test written in Java that IBM had run on CPUs and then accelerated with GPUs, and on small datasets (32 KB) the GPU delivered at 2X speedup and on large arrays (a little over 720 MB) the speedup was a factor of 48X faster. IBM did not say how it did this test, but it is a guess that IBM put some of the C libraries for the CUDA environment in a Java wrapper and made them callable from Java programs.
At the GTC conference last week, Keith Campbell, a senior software engineer at IBM who has worked in the company's Hardware Acceleration Laboratory for the past two years and who specializes in applying acceleration hardware to enterprise workloads, said that IBM wanted to make using GPUs to accelerate Java code a lot easier as well as boosting performance.
"Some of that usage will happen transparently, and will be built into the class libraries that people are accustomed to using and there will be recognition of the GPU when it is present," Campbell explained. "But we are also going to build infrastructure that allow people to interact more with the GPUs at a direct level."
The first step is a framework that IBM is building with the help of Nvidia, one of its partners in the OpenPower Foundation to promote the use of Power processors as an alternative to X86 and ARM chips. This framework will take the CUDA device APIs and the CUDA runtime APIs and bundle them into Java classes to make interacting with GPUs more natural for Java programmers, Campbell said. This will allow them to do data transfers and launch GPU kernels from within their Java applications and gain experience writing hybrid ceepie-geepie code.
To put the early edition of this Java GPU offload framework to the test, Campbell grabbed a workload, called K means clustering, that is used in the Apache Mahout machine learning add-on to Hadoop as well as many other analytics software stacks. The K means clustering method is arguably the most popular of clustering algorithms to sort data into natural piles and was originally developed for signal processing several decades ago by multiple researchers (including Bell Labs).
Campbell said that K means clustering is useful "when you have a lot of data and you are not sure what to make of it." For example, a retailer might have a few petabytes of sales and weblog data and try to reckon what customers can be grouped together based on a set of criteria to then pitch them all a similar deal. The K means algorithm is inherently parallel as well as iterative. You take an initial guess at how many different clusters you might find in the data, and you run the algorithm and based on what you see, you input a new cluster value (that is what the K is short for) and do it again until the data converges.
"What the algorithm is doing is computing the distance from each of those data points to each of the centers it has," Campbell explained." If you have K centers and N points, then you are doing K times N operations, but all that work can be done in parallel because there is no dependency on different data points for the answers. So we can logically think of this as a Map process in the MapReduce framework." The reduction phase merely adds up all of these indices, and the result is the number of points that are nearest to a converged cluster. Here's what the dataset IBM used in the test resulted in:
In this case, the data converged after about 25 iterations of the K means algorithm. In the chart below, the CPU-only Hadoop system only got through five iterations when the GPU-accelerated Hadoop system was able to complete it to the full 25 iterations.
IBM tested the GPU-accelerated Mahout implementation against the CPU-only variant on a number of different tests with different cluster values (K) and data dimension values (D). As you can see, the speedup for the K means algorithm running atop Hadoop is quite large as the number of compared fields remains low and diminishes as the dimensions increase. As the cluster values rise, the gap between the CPU and GPU implementations increases.
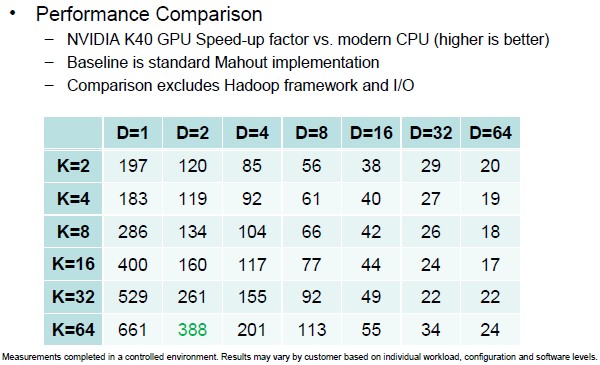
Note: Not all of the Apache Mahout K means code is running on the GPU, but rather just a mapper class that takes all the data points, does the clustering math, and then returns a partial reduction to the host servers. IBM wants that this test excluded the overhead from the Hadoop framework and its I/O and that this was also a lab environment, not a commercial one. With that overhead on there, the speedup looks like it is on the order of about 8X for the entire K means routine, and this is consistent with the roughly 10X speedup that many parallel supercomputing applications written in Fortran or C++ are seeing if they are amenable to GPU offloading.
"This is a foundation that we are using, and what we are hoping to do is use the lambda expressions that are coming in Java 8," said Campbell. "Lambda expressions allow you to express concisely operations that you need to do and you can package that together with arbitrary data structures and you can express computations without worrying about the order of these things. When order doesn't matter, these are good candidates for offloading to the GPU. For some cases, we will cherry-pick a few things, but the hope is that this all happens behind the scenes without applications having to do anything special."
Campbell said that Java 8 had a bunch of forward-thinking classes that were designed from the get-go for multicore processors and highly parallel architectures.
"Further down the road, we will also have to consider how to arrange that the data is in a format that is convenient for operation by the GPU," Campbell continued. "IBM has been talking about PackedObjects for a while, Oracle has its own ideas about how things need to happen, and we are working with them and the OpenJDK community to make sure we have solutions to these problems."
The OpenPower software stack for hybrid computing
It won't be too long before Java shops can boost the performance of applications running on Power-based machines that use the Linux operating system and have Nvidia Tesla GPU coprocessors. Ken Rozendal, who is chief architect for IBM's Linux Technology Center and who has done lots of work on the guts of IBM's AIX Unix operating system variant, said in the GTC session that Nvidia and IBM would deliver a CUDA toolkit and runtime environment for Power-based systems in the third quarter of this year.
This combined CUDA and IBM toolkit is being made available for Linux, and it could turn out that IBM does not make it available for its own AIX and IBM i (formerly OS/400) operating systems until there is sufficient demand. The financial services, oil and gas, and manufacturing customers who are the most likely to use the Power-Tesla combination are also more likely to have ported their applications to Linux many years ago.
The Power-Linux toolchain, which is being expanded through the efforts of the OpenPower Foundation, also includes the KVM virtual machine hypervisor running on Power and the OpenStack cloud controller that is usually associated with it these days. For interpreted language such as Java, JavaScript, PHP, Perl, Python, and Ruby, porting code from X86 to Power is no big deal; the runtimes take care of that since the code is only compiled inside of them when they execute. Code written in C, C++, or Fortran does take a recompile, but Rozendal says this is also not a big issue these days.
"Sometimes, people made assumptions about the way page sizes work or memory ordering works when they wrote their code," he said. "These are rare, we don't see them in most of the software we deal with, but it is possible to have these kinds of dependences in your code."
The problem that IBM does have is that not many programmers have a Power platform on their desktops these days. (If Apple had not jumped from PowerPC to X86 chips back in 2006, this might be a different thing.) So IBM is taking the Eclipse-based PowerLinux software development kit, which includes the GNU compilers, the LLVM compiler tools, and its own JVM as well as the OpenJDK JVM, and wrapping it all up together. The software stack is aware of Power, and allows for code to be tested and tuned on a Power chip emulator that runs on top of X86 iron – this is called Mambo and it was created by IBM Research – or on local or remote Power Systems machines. IBM is also weaving in a bunch of its own tools for threading applications and probing code, but these are only shareware, not open source.






