



PCI Express Switching Takes On Ethernet, InfiniBand

Ethernet, InfiniBand, and the handful of high-speed, low-latency interconnects that have been designed for supercomputers and large shared memory systems are going to soon have a new rival: PCI-Express switching.
The idea might sound a bit strange, but it bears some consideration. Particularly with two companies – PLX Technologies and A3Cube – readying two different extensions of the PCI-Express point-to-point interconnect, used as a peripheral interconnect inside modern servers, that will allow it to act like a switch between servers. In both cases, the idea is to eliminate some of the electronics and cost of clustering machines together while at the same time providing the same lower latency than Ethernet or InfiniBand switching can deliver.
Taking on Ethernet as the interconnect for clustered systems is tough. History is littered with alternatives that are no longer on the market, including a slew of proprietary technologies developed by supercomputer and telecom equipment makers as well as more broadly adopted approaches such as Token Ring. (Remember that?) Even those high-end interconnects that have significant advantages over Ethernet struggle for market share against Ethernet, which has the habit of stealing most good ideas in networking and incorporating them into the latest update of its protocol. But in a world with computing and networking divergent needs, there is a place for other interconnection schemes, and that is why PCI-Express switching might find its niches and grow from there.
Intel sells Ethernet switch chips and adapters, but it has also acquired the “Gemini” and “Aries” interconnects developed by Cray for its supercomputers, and the two companies are committed to creating future interconnects that can scale systems up towards the exascale stratosphere in supercomputing. SGI similarly continues to invest in its NUMAlink low-latency interconnect, which does not scale as far but which has the virtue of gluing nodes in a Xeon cluster into a giant shared memory machine. NumaScale offers a similar NUMA interconnect that can be used to create shared memory machines. InfiniBand, like the Cray interconnects, is not designed for tightly coupling machines so nodes can create a single shared memory space, but it has also found its place in the modern datacenter. Other new and proprietary interconnects still come to market from time to time, such as the Freedom Fabric created by SeaMicro for its microservers and now controlled by AMD.
InfiniBand was designed as a kind of universal I/O interconnect, and the idea was to use it as a switching fabric to link servers to clients, servers to each other, and servers to storage. Thanks to Remote Direct Memory Access (RDMA), InfiniBand instead found its niche in supercomputing because of the substantially lower latency it provided compared to Ethernet. InfiniBand had a bandwidth advantage for many years, too. But in recent years, as Ethernet has borrowed RDMA from InfiniBand and ramped up the bandwidth, too, the gap has closed some. But even still, InfiniBand continues to expand into high-end storage clusters as well as in an increasing number of public clouds.
It would seem that all of the interconnect bases are covered, and the last thing the IT industry needs is another option. Not so say both PLX, which has been selling PCI-Express switching chips to extend system peripheral interconnects for many years, and A3Cube, a startup that has come up with its own twist on PCI-Express switching for linking systems to each other for compute or storage clustering.
There have been other attempts to extend PCI out to be a system interconnect, explains Larry Chisvin, vice president of strategic initiatives at PLX, which is a public company that sells chips used in PCI-Express adapters and switches.
A company called StarGen worked with Intel and Integrated Device Technologies to come up with a PCI switching scheme called Advanced Switching, which came to market more than a decade ago and after InfiniBand, which itself championed by Intel and IBM and is the result of from two formerly diverse I/O projects that were turned into an advanced switching alternative to Ethernet. So there is some precedent for this kind of transformation happening. The PCI Special Interest Group standards body that controls the PCI did Multi-Route I/O Virtualization (MRIOV) for sharing devices across multiple hosts and which could, in theory, be tweaked to be a system interconnect. But, says Chisvin, MRIOV required new switches, new endpoints, and a new software stack and therefore did not take off as an interconnect.
What many would like, and what we can’t get to for a variety of technical, economic, and emotional reasons, is a converged point-to-point fabric that links disaggregated components. We are getting such convergence in a piecemeal fashion, such as Cisco Systems championing the Fibre Channel storage protocol over 10 Gb/sec Ethernet as the converged fabric inside of its Unified Computing System blade servers. FCoE has been adopted by all the major switch and server makers to link external SAN arrays to compute farms over Ethernet.
The PCI-Express switching efforts from PLX and A3Cube are also based on the idea of convergence, only in this case the idea is to allow for Ethernet network traffic to run over PCI-Express switching infrastructure without having to run a full and fat Ethernet stack inside the operating system. There is some precedent for this idea as well, and it comes from none other than Cray. The supercomputer created a software layer called the Cluster Compatibility Mode that allowed for applications written for standard Linux clusters connected by Ethernet protocols to run atop of its SeaStar and Gemini interconnects in an emulated mode.
“It is immediately obvious that there are a lot of extra parts in a system and a rack of systems,” explains Chisvin. “And the thing to note is that all of these devices start off as PCI-Express. Since almost every component – CPUs, storage devices like hard disks or flash, communications devices, FPGAs, ASICs, whatever – all have PCI-Express coming out of them, and so there is really no need to translate it to something else and then translate it back. If you could keep it in PCI-Express, then you eliminate a lot of the fairly expensive and power-hungry bridging devices. A 10 Gb/sec Ethernet card is anywhere from $300 to $500 and it dissipates 5 to 10 watts, and if you multiply that out for a rack of servers, the math gets pretty easy.”
That’s why PLX is cooking up what it calls ExpressFabric, and as the name suggests it is an interconnect fabric based on PCI-Express that makes it look and feel more like a network interconnect for systems and storage.
Chisvin says that using PCI-Express as a switching fabric inside of a rack or across a couple of racks requires a combination of a retimer and a redriver, which are two special circuits that recondition and amplify the PCI signals so they can be sent over longer distances than normal PCI-Express links. These circuits burn under 1 watt of juice and cost in the order of $5 a pop. (Smaller systems do not need retimers and redrivers, you just plunk a PCI-Express switch in the middle of the box and go.)
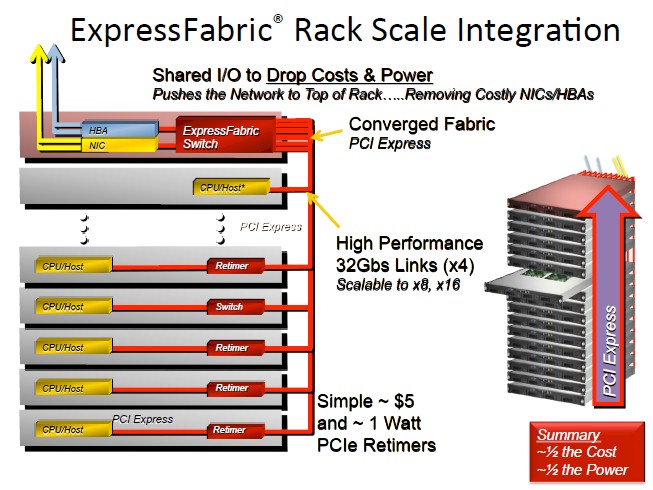
So why has PCI-Express not already conquered the datacenter as an interconnect? Because garden-variety PCI-Express does not have the features necessary. Chisvin says that there are ways to use raw PCI-Express switches to link systems together, but that it cannot be done very easily.
“You can’t really hook all of these things up without changing the software,” he says. “And so with ExpressFabric we have taken PCI-Express and extended it on top of the spec so you can do this. The PCI spec allows you to add vendor-defined extensions and our changes are compatible. What that means is that standard, existing PCI components can be used without any change. And that is key. So we decided to put everything you need for converged networks inside of the switch. We do not insist on changes in endpoints or software. And all of these devices, when hooked together, talk to each other just like they are next door to each other.”
ExpressFabric switches are in development now and early adopter customers are playing with them right now, says Chisvin. PLX expects to have ExpressFabric out the door by the end of the year, and Chisvin says that the ExpressFabric switch will bear some resemblance to the current PEX 8798 switches that PLX already sells. These have 24 ports and a total of 96 lanes of traffic and a port-to-port latency of around 150 nanoseconds. If you want to build a network that has more than 24 devices, you use multiple switches and hook them together in any number of connection topologies. Any topology commonly used for point-to-point interconnects – mesh, fat tree, 2D or 3D torus, hypercube, whatever – can be used to link multiple switches together. Of course, each hop from switch to switch adds latency.
PLX is not targeting warehouse-scale datacenters, as the Googleplexes of the world are called, with ExpressFabric, but is rather thinking on a smaller scale, from hundreds to thousands of nodes in many one to eight racks. Companies will be able to use QSFP+ cables commonly used for Ethernet and InfiniBand to link nodes together, or MiniSAS-HD cables if they want to go that route. Any cable that can support the 8 Gb/sec transfer speed of the PCI-Express 3.0 protocol can be used. Other kinds of optical cables or chassis backplanes will also be deployed, depending on the circumstances.
PLX has not run benchmarks on ExpressFabric as yet, since the product is not yet completed, but it has done internal simulations to figure out its potential against alternatives.
“Take QDR InfiniBand, for example,” says Chisvin. “We have the same bandwidth as QDR and our RDMA engine is very similar. So an OFED application running on our hardware should be similar because it is the same speed and it is very similar hardware.”
Just a reminder that PCI-Express 3.0 offers 8 Gb/sec per lane per direction, and devices can support 2, 4, 8, or 16 lanes depending on their bandwidth needs. With PCI-Express 4.0, the bandwidth per lane will double up to 16 Gb/sec and the lane counts will remain the same. Chisvin says he personally expects for PCI-Express 4.0 to come our no earlier than the second half of 2016 and no later than the end of 2017.
Over at upstart A3Cube, which launched its own variant of PCI-Express switching two weeks ago, the company is embedding a distributed PCI-Express switch into a server interface card that will allow it to look like an Ethernet device to software but replace top-of-rack and end-of-row switches in a cluster. And the company has larger ambitions in terms of cluster scalability than PLX, says Emilio Billi, co-founder and CTO at A3Cube.
A3Cube was founded in 2012 after more than five years of research and development into switching alternatives. The company has filed patents for a distributed non-transparent bridging technique for PCI-Express switches, for a PCI-Express multiport switch adapter cards, and for a massively parallel storage system that scales to petabytes using its hardware designs. (These patents have not been granted yet by the US Patent and Trademark Office.)
The A3Cube setup is a bit complex, but here is the gist of it as Billi explained it to EnterpriseTech. As PLX is doing, A3Cube has to add features to PCI-Express to make it a true network interconnect, such as flow control and congestion management.
“We want to use the memory address of the PCI-Express mapping,” Billi says. “We do not want to encapsulate something else on top of PCI-Express and therefore create a latency, but rather use the same mechanisms that are used natively and locally in PCI-Express but use them across the network through memory mapping. We create a TCP/UDP socket that uses this mechanism for communication, bypassing the software in the operating system. At the end of the story, we reduce the latency to the minimum possible without losing the compatibility with TCP/UDP applications.”
Billi says that 90 percent of the applications in the world speak TCP/IP, and being compatible with those applications was the central goal of the switch adapter cards that A3Cube has engineered, which are called Ronniee. At the protocol level, what A3Cube has created is a TCP over DMA implementation that rides on top of PCI-Express 3.0. The setup uses “memory windows” to access data on each host system and creates a global, shared 64-bit memory space that implements the fabric.

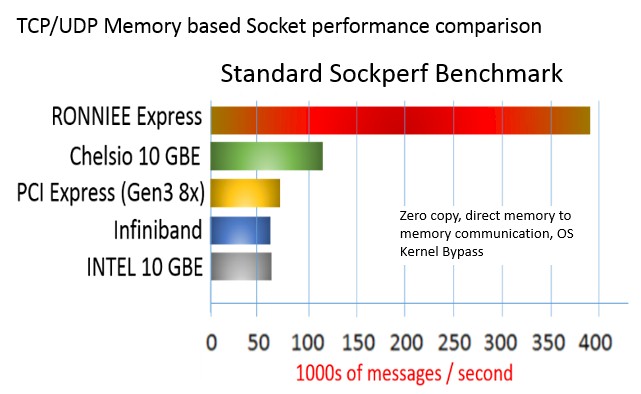
This fabric allows for communication between processors, memory, and I/O devices across that space, either locally inside of a system or across nodes in a cluster. The coupling of nodes is not fast enough for the cluster to run a single instance of an operating system. But it is plenty fast enough to run clustered applications. The host-to-host latency running TCP-style applications (one that is not rewritten to take advantage of RDMA) is around 2.5 microseconds, says Billi, compared to around 3.3 microseconds for servers using a 10 Gb/sec Ethernet card from Intel. For direct memory accesses, the performance gap opens up even more, with The Ronnie Express card being able to handle close to 400,000 messages per second using DMA, nearly four times as fast as a Chelsio 10 Gb/sec card that is the gold standard in high speed Ethernet. On other tests RDMA, the Ronniee distributed PCI switch was able to do point-to-point hops in 720 to 730 nanoseconds, about the same as FDR InfiniBand, Billi claimed.
Billi says that A3Cube has developed a native MPI stack for its PCI-Express switching using the MPI-2 stack, and adds that the company is working on a driver for MPI-3 right now to get even more performance. And if you want to compare the Ronniee switching to a traditional supercomputer, then Billi says his setup can do 1.56 microsecond latencies on a cluster compared to 1.5 microseconds for a Cray system using the Gemini interconnect. (Cray’s Aries is a lot faster and higher bandwidth than Gemini, of course.)
A3Cube is shipping three different hardware components and a software stack to implement the memory-based fabric. The Ronniee 2S card implements a 2D torus interconnect for nodes in a cluster and can scale to hundreds of nodes, in theory. The Ronniee Rio card can scale from up to 64,000 nodes using a 3D torus topology; you can also use hypercube topologies. The high-end switch card uses a routing algorithm across that distributed memory bridge to accomplish that scale. On a system with 25,000 nodes, Billi estimates that the maximum latency between any two nodes will be 10 microseconds. Thus far, A3Cube has only tested its setup on a 128-node cluster, so it probably makes sense for someone to test the limits a bit further. The Ronnie 3 is a chassis that can have up to a dozen of the Ronniee 2S cards plugged into it and that has the look and feel of a switch for those who don’t want to put the devices inside of the servers.
A3Cube will ship the Ronniee 2S, Rio, and Ronnie 3 devices in the second quarter. The company is being vague about pricing, but when pressed by EnterpriseTech Billi said that a high-end Ethernet card with TCP/IP offload would cost around $900 and that his goal was for the Ronnie 2S card to be 25 to 30 percent lower than this price.
On the software side, the distributed PCI-Express switching setup comes with a bunch of device drivers and libraries that run on top of any Linux distribution with the 2.6.30 or higher kernel. A3Cube has bundled up these libraries with the CentOS clone of Red Hat Enterprise Linux to create what it calls ByOS if you want something that is easy to install. This ByOS created some confusion at launch time two weeks ago because many thought A3Cube’s clustering required its own operating system. This is not so, and in fact, the company is working on a version of the software stack that will run on Windows, which could be ready by summer. Solaris could be next. Thus far, A3Cube is only interested in X86 machinery, but that could also change.
A3Cube is working with a handful of beta customers and is in discussions with a few OEM resellers, but cannot provide specifics yet.






