



Facebook Whips Systems Into Shape With Customized Chef
Like many modern corporations that exist mainly to supply a service over the Internet, Facebook would like to use open source software wherever practical in its infrastructure and with as little change as possible. But given the immense scale that the social network operates at – it has hundreds of thousands of servers operating in its three datacenters and handful of colocation facilities – that is not always possible.
Sometimes hacking an existing project does the trick, and that is the case with Facebook and the Chef configuration management tool.
In some cases, companies operating at scale have to add features to an open source project to make it scale better, as was the case with LinkedIn and its use of the open source CFEngine configuration management tool. LinkedIn ran up against the scalability limits of CFEngine, more because the system discovery process and figuring out what of its 30,000 systems to patch was still largely manual, and so it created a Redis NoSQL data store backend for CFEngine to keep all the telemetry on its fleet and allow of instantaneous querying to figure out what machines were configured in what way.
Facebook's first system configuration automation tool was also CFEngine, Phil Dibowitz, a systems engineer at Facebook, explains to EnterpriseTech. Facebook started out on CFEngine 2 many years ago – long before Dibowitz came to the company in 2010 – but for a number of different reasons the company started looking for alternatives.
Dibowitz was hired to do the looking. He was a Solaris and Linux systems administrator in the wake of the dot-com bust some service providers, spent a few years as a systems architect at the University of Southern California, and was a senior Unix systems administrator at Ticketmaster for several years. While at Ticketmaster, Dibowitz was one of the creators of the open source Spine configuration tool, which controls the setup of the 3,000 Linux servers in the ticket broker's datacenters today. Spine is a hierarchical tool that is meant to simplify the way systems get configured by grouping them in classes, and it works well for setups where you have groups of machines doing similar tasks with similar iron. Dibowitz also created the Provision server provisioning companion to Spine while at Ticketmaster before he went to Google for a two-year stint as a site reliability engineer. (That's the closest thing to a system administrator that Google has, and it is a much broader and deeper role.)
"We did a lot of work in evaluating all possible configuration management systems that exist in the world," says Dibowitz. "As you might imagine, we were not thrilled with the idea of writing out own, so the question was is there something we can use or build on."
Lots of different tools were tested by Dibowitz and his team of three configuration management engineers, who manage all of those hundreds of thousands of servers. (Well, sort of. More on that in a moment.) The three contenders for a replacement to CFEngine were Spine, Puppet from Puppet Labs and Chef from Chef Software (formerly known as Opscode).
"Chef was chosen as the tool that was going to fit our workflow the best," says Dibowitz, "and the primary reason was flexibility because everything in Chef is just Ruby executed at different stages and there is really nothing that you can't do. It is just a programming language and you are just evaluating Ruby. There is lots of syntactic sugar on top of that to enable things to be easier."
It is funny about the choices that companies make. LinkedIn chose CFEngine for its configuration management tool because it is written in C++ for high performance and specifically because it did not have any dependencies on any outside languages. Most configuration tools have a domain specific language, according to Dibowitz, but they are not full programming languages like Ruby. "You can define resources that you want to manage, but only within the framework of their specific language. So you can't necessarily loop over your resources or dynamically generate your resources. You are just more limited in how you can manage things using other tools."
The other benefit of Chef is that a lot of its work gets done on the Facebook servers themselves (which is called clients by Chef, of course, just to keep it interesting. "Almost nothing is centralized, so it is so much easier to scale everything," according to Dibowitz.
Dibowitz is not allowed to talk precisely about how many servers that Facebook has in production or where they are located. But generally speaking, each cluster at Facebook has something on the order of 15,000 servers, give or take a few thousand. There are multiple clusters in a datacenter and multiple datacenters in a region. The three main production regions at Facebook are in Prineville, Oregon; Forest City, North Carolina; and Lulea, Sweden, plus the co-location facilities in California in San Jose and Santa Clara. (Facebook is looking to get out of Silicon Valley because the datacenter and power costs are too high, and will probably do so about the time that its wind-powered Altoona, Iowa facility comes online in early 2015.)
That 15,000-node cluster is controlled by a single Chef server instance, but Facebook has an untypical configuration of the Chef Enterprise or the open source Chef server to do so. The upgrade from CFEngine to Chef is still ongoing, but at this point about 85 percent of the machines in the Facebook fleet have their configurations managed by Chef. Here's what it looks like:
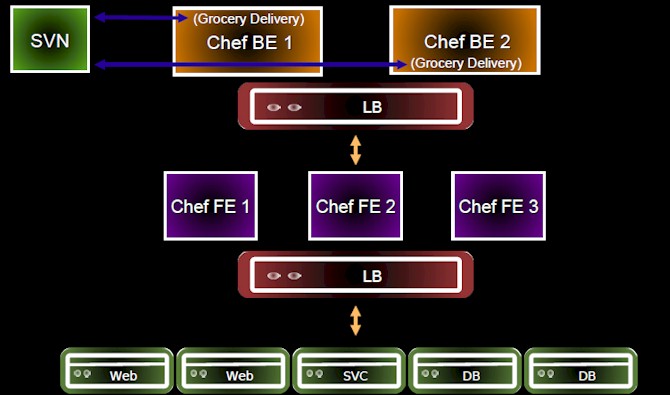
The Chef Enterprise server is broken into a front end and a back end, and each Facebook cluster has three Chef front ends, which have the requests for changes to server configuration templates– called cookbooks – load balanced across them. The two back-end Chef Enterprise servers are clustered for high availability. Facebook has made a number of modifications to the Chef tool so it can scale. On one cluster with 17,000 server nodes checking in every fifteen minutes for configuration updates, those two back-end servers consume about 85 percent of their CPU capacity.
To let a pair of back-end machines handle such a load, Facebook has to turn a lot of stuff off. First, Facebook disabled the Chef search functions, which eat a lot of resources. Next, Facebook disabled the Ohai introspection feature on the Chef server, which looks at everything – what file systems are present, what kernel modules are loaded, you name it – on each node. When you make changes to a node, the file describing the setup has to be saved back to the Chef server. This "node save" function is popular because it basically gives Chef shops an inventory management system for free. Facebook already has one of those.
Dibowitz said all of this moving of data back and forth between the Chef server and the cluster nodes for node saves "would melt our switches," so Facebook created a Chef cookbook that kept that data locally on Facebook servers, but did not save it back to the Chef server over the network.
Facebook has homegrown hardware inventory management tools to figure out what server has what stuff in it. The company does not use Chef for application deployment because it has a homegrown tool for that as well, and this means the Chef server has more capacity to dedicate to configuration management. Both homegrown application deployment and inventory management tools as well as a homegrown system monitoring tool are subject to replacement as soon open source projects get good enough and can scale far enough.
Another tweak that Facebook created for Chef is called Grocery Delivery, which is a Chef extension that the company has contributed back to the open source community. Grocery Delivery is necessary because Chef does not have the capability to manage multiple clusters, and it automatically updates the Chef server back-ends with new cookbooks as the administration team or software engineers responsible for various services make changes to cookbooks. The way Chef is deployed, the server runs every 15 minutes, looking for configuration changes, and it takes 14 minutes to pump those changes out across the cluster. It has a sophisticated hashing mechanism for tracking changes, so it can very quickly see what has changed and pump the configurations out across the server nodes. Any change takes under 30 minutes to propagate to those 15,000 machines.
That's the other interesting thing about Facebook. The company does not have a global group of system administrators, like Google's site reliability engineer SWAT team. It does have a few production engineers for a handful of different product groups, which have somewhere between two and ten people on a team. But by and large, it is the software engineers who are coding for the Facebook services who are making changes to cookbooks.
The Facebook cookbooks for server configuration are a bit different from the standard ones, too. They are really a set of APIs that create a template, using a hash of key-value pairs, for the most typical server setups at the company, but leaving software engineers the ability to make tweaks for the portions of a server setup they are knowledgeable about – say, the memory capacity for a MySQL database instance supporting a particular workload – without having to know about or deal with the other aspects of the system. One change of a few lines in the master cookbook is sent out instantly to the relevant machines in the cluster and is again running in under 30 minutes.
"You can't have as many people as you have servers," says Dibowitz with a laugh. "This way, I get to manage the features of the system that I am the expert at, and you get to manage the things that you are expert at, and everyone, as people, get to scale better. This was one of the goals we had for moving from CFEngine to Chef. Not to necessarily make the system management scale better. As it turns out, if you have enough system engineers, you can make a configuration system scale. The real goal was to have people scale better, and have fewer people have to wrap their minds around incomprehensible combinations of configurations."
Another interesting thing: At any given time, somewhere between 20 and 25 percent of the clusters in the Facebook fleet will always run the open source version of Chef rather than the commercial-grade Chef Enterprise. That is because Facebook has promised to work with the Chef community to make sure that the freebie version of the code can scale and is stable.






